A complement to Object Encapsulation
Posted by Petter Måhlén in Software Development on January 20, 2012
As usual, I’ve been thinking about Maven and how it’s not perfect. As usual, I really want to fix it, but have no time to actually do something. This time, the issue I found made me think about something that is kind of a complement to encapsulation, but I don’t know if there’s a proper term for it. I’ve asked 5-6 people who ought to know, but none of them has come up with something, so I’ve decided to call it self-sufficiency until somebody can tell me what it is really called. :)
Let’s start with the issue that got me thinking. We have started using Clover to measure code coverage of our tests, and the first take on a standardised POM file for building a set of new components led to some weird things happening. Such as executing the ‘javadoc:jar’ goal 12 times in a single build, and so on. I never figured out exactly how that happened, but I managed to track the problem down to the fact that the Clover2 plugin calls the ‘install’ phase before executing itself. Although I think that is a less than great thing to do, there’s probably a good reason why it needs to ensure that ‘install’ has been executed, and I don’t want to spend time on that particular issue. What’s interesting is that this is a symptom of a design flaw in Maven. Maven allows and almost encourages plugins to be aware of and manipulate the build in its entirety – by registering themselves with a specific lifecycle phase, by letting them pull information out of the global project structure and like in this case, by allowing them to manipulate the build flow.
This reaching out of one’s own space into a global space, where an object makes assumptions about what the world surrounding it looks like, is what I mean by the ‘complement of encapsulation’. An object that makes no such assumptions and does no such reaching out is self-sufficient.

To give a little more meat to the idea I’m trying to describe, here’s a list of related concepts and why they’re not the same:
- Encapsulation – it’s probably incorrect to think of self-sufficiency as the complement of encapsulation. They’re certainly not each other’s opposites, and encapsulation isn’t enough to guarantee self-sufficiency. It is perfectly possible that in the Maven example above, there is a well-encapsulated object that manages the build cycle, which the plugin is calling. The concept of encapsulation is applicable at an object or class level, whereas the concept of self-sufficiency is more of an architectural concept – what kind of interactions you decide to allow between which (sets of) objects.
- Dependency injection – one of the main points of dependency injection or inversion of control is that it encourages and enables self-sufficiency. Without it, objects always reach out into the surrounding world, making assumptions about what they will be able to find. But again, like encapsulation, DI works at a different level, and is not quite sufficient to get self-sufficiency.
- Side effects – there are many different definitions of side effects, but with all I’ve seen, the concept of self-sufficiency is related but not identical. Side effects are usually considered be “something that I didn’t expect a method with name X to do”. It’s possible and not uncommon to have objects that are not self-sufficient but are side-effect-free.
- Coupling – as I interpret the wikipedia definition, I would say that in order for a system to be loosely coupled, it must have self-sufficient objects. However, having self-sufficient objects isn’t enough to guarantee loose coupling – the most common application of the term relates to lower-level coupling between classes, making it harder or easier to swap in and out concrete implementations of collaborators. You can have self-sufficient objects that are strongly coupled to specific implementations of their collaborating objects rather than interfaces.
- Law of Demeter – an object that violates the Law of Demeter is less self-sufficient than one that follows it. But again, the Law of Demeter is more of a class/object design principle, and the principle of self-sufficiency is an architectural one. You can violate the principle of self-sufficiency while keeping strictly to the Law of Demeter.
- Layering – this is very closely related. Violating the principle of self-sufficiency means you’re bridging abstraction layers. Ideally, a Maven plugin should be at a layer below the main build itself (or above, depending on which direction you prefer – in this discussion, I’m saying lower layers cannot call up into higher layers). The main build should provide the plugin with everything it needs, and the plugin should execute in isolation and without worrying about what happens above it. Self-sufficiency is a narrower and slightly different concept than layering. It has opinions on where the layer boundaries should be located. In the Maven example, there is no abstraction layer between the build as a whole and the plugins, and self-sufficiency states that there should have been one.
I’m not sure self-sufficiency is a great term, so if somebody has an idea for a better one, please feel free to make suggestions! Here are some other terms I thought of:
- Isolation – objects that are self-sufficient can be executed in isolation, independently of the context they’re running in. However, isolation would be overloaded (with primarily the I in ACID), and it’s also a little negative. I think the term should be positively charged, as the concept represents a good thing.
- Introvert/Extrovert – an Extrovert object reaches out into the world and makes assumptions about it whereas an Introvert one has all it needs internally. The good thing about this pair is that it is a pair. The world in-self-sufficient doesn’t work, and neither does self-insufficient. But again, the way these terms are usually used, it’s better to be an extrovert than an introvert, which is the opposite of what the term should mean in this context.
If I ever do find the time to try to fix Maven, one of the things I’ll do is make sure plugins are self-sufficient – let the overall build flow be controlled in its entirety by one layer, and let the plugins execute in another layer, in complete ignorance of other plugins and phases of the build!
Do NoSQL databases make consistency too hard?
Posted by Petter Måhlén in Software Development on October 18, 2011
I’ve spent the last couple of weeks trying to figure out how to design a fairly large system that needs to deal with hundreds of millions of objects and tens of thousands of transactions per second (both reads and writes). That kind of throughput is hard to do with a traditional RDBMS, although there are apparently some people that manage. The problem is those tricks seem to be very much about getting amazing performance out of single database nodes, and of course, if you run out of tricks when the load increases, you’re screwed. What I’m looking for is something that is more or less guaranteed to scale. In this particular case, availability and partition-tolerance are not very important as such, but consistency and scalable throughput are, as is the ability to recover reasonably quickly from disasters. Scalability and throughput is what you get from NoSQL systems, so that would seem to be the way to go.
The problem with NoSQL is of course the relaxation of consistency. Objects are replicated to different nodes, and this may lead to updates that create conflicting versions. These conflicts need to be detected and resolved. And that is hard to do. Detection is usually a bit easier than resolution, but there is a lot of variation in when it happens. Here are a few relatively common options for conflict resolution (that is, how to figure out the correct value when a conflict has been detected):
- Automatically using some version of ‘last writer wins’, perhaps augmented using vector clocks or something similar to increase the likelihood of being correct. This is only a likelihood, though, and at least for our current case, this is insufficient.
- Let readers resolve conflicts by giving them multiple versions of the data, if there have been conflicts (this is how Amazon’s Dynamo works, by the way).
- Make it possible for writers to resolve conflicts by presenting them with the current versions in case there are conflicts, or using something like a conditional put.
All of those are hard to do in a way that is correct, algorithmically efficient and doesn’t waste space by storing lots of transaction history. But there seems to be some hope: two of the most interesting papers I’ve read are (co-)authored by the same guy, Pat Helland. If I understand him right, he argues for a type of solution that is subtly different from all the NoSQL solutions I’ve come across so far. The salient points, in my opinion, are:
- Separate the system into two layers, a scale-agnostic business layer that knows how to process messages, but is completely and utterly unaware of the scale at which the system is running, and a scale-aware layer that has no idea what business logic is executed but that knows how many nodes are running and how data is distributed across the different nodes.
- Ensure that all business-level events triggered by messages are Associative, Commutative and Idempotent (adding Distributed into the mix, he calls this ACID2.0, I’ll use ACI for the first three letters from now on). This means that if two nodes have seen the same messages, they will have the same view of the world, irrespective of the order in which they arrive, and whether they received one or more copies of a particular message.
- Ensure that the scale-aware layer guarantees at-least once delivery of messages. That is, a sender can rely on the fact that a message will always arrive at the right destination, even in the face of failures, repartitioning of data, etc. The only way to do that is to occasionally have messages arrive more than once.
With a system that follows those principles, conflicts don’t happen, so you don’t need to resolve them. Think about that for a second – associativity and commutativity means that message processing is order-independent. Idempotence means that if you receive the same message twice, the second time has no effect. This means that any differences in world-view (that is, data stored locally) between two different nodes will always be resolved as soon as they have seen the same set of messages, which is essentially the definition of eventually consistent. At-least-once message delivery guarantees that all nodes that should receive a certain message will do so, sooner or later.
The key difference between Pat Helland’s architecture and today’s NoSQL solutions is the level at which world-view coordination is done. As far as I can understand, all current NoSQL systems coordinate at the data level by making sure that bits and bytes are propagated to the right receivers in the clusters. The problem is that once those bits and bytes differ, it is very hard to understand why they differ and what to do about the conflict. There’s no generic way, at the data level, to make messages ACI, but it can be done at the business logic level. The data-replicating systems don’t and can’t realistically preserve the business-level events that led to the changes in data.
It is hard to design a system whose operations are all ACI, but it is also hard to design a system that is guaranteed to resolve conflicts correctly. In the case I’m currently working on, it’s been far easier to figure out how to make business-level events associative, commutative and idempotent rather than deal with the conflicts – I feel my thinking about these concepts is still very naive, so I have no knowledge of whether that translates to most other problems or not. In fact, I should probably say I’m not sure that it is actually the case for our system either as it’s not been implemented yet. Ask me again in six months’ time. :)
It certainly does feel like replicating at the data level makes things harder, and instead replicating business-level messages that trigger ACI operations would make for a more natural architecture. The closest I’ve seen to a system that does that is SQLFire, which is in fact where I first found the reference to the “Life Beyond Distributed Transactions” paper. SQLFire uses the entity concept from “Life Beyond Distributed Transactions”, but as far as I can tell (their documentation isn’t great right now, and renders very poorly on Chrome), SQLFire, too, appears to do replication on the data level as opposed to the level of business messages. I’d be very interested in seeing how a NoSQL solution would pan out that just provided the scale-aware distribution layer that Pat Helland mentions. You wouldn’t even necessarily have to include the data stores in such a solution – that could be done in RDBMS:s for each node if you want those semantics, or using in-memory caches, or whatever. Maybe we’ll develop such a system in this project – highly unlikely as I don’t think that would be money well spent. That it would be fun is of course not a good-enough reason…
If it’s Broken, Fix It
Posted by Petter Måhlén in Software Development on April 8, 2011
A search for terms like “bug classification” or “bug priority” gives a lot of results with lots of information about how to distinguish bug severity from bug priority, methods to use to ensure that you only fix the relevant bugs, what the correct set of severities are (is it Blocker, Major, Minor, Cosmetic, or should there be a Critical in there as well?), and so on. More and more, I’m starting to think that all that is mostly rubbish, and things are actually a lot simpler. In 95% of the cases, if you have found a bug, you should fix it right then and there, without wasting any time on prioritising or classifying it. Here’s why:

Fixing a bug means you incur a cost, and that’s the reason why people want to avoid fixing bugs that aren’t important. Cost-cutting is a great thing. The problem is, not fixing a bug also has a cost. If you decide to leave some inconsequential thing broken in your system, most likely, you’ll run into the same thing again three months down the line, by which time you’ll have forgotten that you had ever seen it before. Or, equally likely, somebody else will run into it next week. Each time somebody finds the thing again, you’ll waste a couple of hours on figuring out what it is, reporting it, classifying and prioritising it, realising it’s a dupe, and then forgetting about it again. Given enough time, that long term cost is going to be larger than the upfront fixing cost that you avoided.
What’s more, just having a process for prioritising bugs is far from free. Usually, you will want the person who does the prioritisation to be a business guy rather than a QA or development guy. Maybe the product owner, if you’re doing Scrum. That means that for every bug, she will have to stop what she is doing, switch contexts and understand the bug. She will want to understand from a developer if it is easy or hard to fix, and she will want to assess the business cost of leaving it unfixed. Then she can select a priority and add it to the queue of bugs that should be fixed. In the mean time, work on the story where the bug was found is stalled, so the QA and developer might have to context switch as well, and do some work on something else for a while – chances are the product owner won’t be available to prioritise bugs at a moment’s notice. Instead, she might be doing that once per day or even less frequently. All this leads to costly context switching, additional communication and waiting time.
The solution I advocate is simple: don’t waste time talking about bugs, just fix them. The majority of bugs can be fixed in 1-5 hours (depending of course on the quality of your code structure). Just having a bug prioritisation process will almost certainly take 1-3 man-hours per bug, since it involves many people and these people need to find the time to talk together so that they all understand enough about the problem. The cost might be even larger if you take context switching and stall times due to slow decision-making into account. And if you add the cost of having to deal with duplicate bugs over time, it’s very hard to argue that you will save anything by not fixing a bug. There are exceptions, of course. First, time is a factor; the decision not to fix will always be cost effective from a very short perspective, and always wasteful from a very long perspective. Second, the harder the bug is to fix, and the less likely it is to happen, the less likely is it that you’ll recover the up-front cost of fixing the bug by avoiding long-term costs due to the bug recurring. I think it should be up to the developer whose job it is to fix the bug to raise his hand if it looks likely to fit into the hard-to-fix-and-unlikely-to-happen category. My experience tells me that less than 5% of all bugs fit into this bucket – I just had a look at the last 40 bugs opened in my current project, and none of those belonged there. Anyway, for those bugs, you will need to make a more careful decision, so you need the cost of a prioritisation process. That means you can reduce the number of bugs you have to prioritise by a factor 20, or perhaps more. Lots less context-switching and administration in the short perspective, and lots less duplicated bug classification work in the longer perspective.
Note that the arguments I’m using are completely independent of the cost of the bug in terms of product quality. I’m just talking about development team productivity, not how end users react to the bug. I was in a discussion the other day with some former colleagues who were complaining that the people in charge of the business didn’t allow them to fix bugs. But the arguments they had been using were all in terms of product quality. That is something that (rightly, I think) tends to make business people suspicious. We as engineers want to make ‘good stuff’. Good quality code that we can be proud of. But the connection between our pride in our work and the company’s bottom line is very tenuous – not nonexistent, but weak. I want to be proud of what I do, and what’s more, I spend almost all of my time immersed in our technical solutions. This gives me a strong bias towards thinking that technical problems are important. A smart business person knows this and takes this into account when weighing any statement I make. But to me, the best argument in favour of fixing almost all bugs without a bug prioritisation process only looks at the team’s productivity. You don’t need the product quality aspect, although product quality and end-user experience is of course an additional reason to fix virtually all bugs.
So, it is true that there are cases when you want to hold off fixing a bug, or even decide to leave it in the system unfixed. But those cases are very rare. In general, if you want to be an effective software development team, don’t make it so complicated. Don’t prioritise bugs. If it’s broken, fix it. You’ll be developing stuff faster and as an added bonus, your users will get a better quality system.
Bygg – Executing the Build
Posted by Petter Måhlén in Java on March 15, 2011
This is the third post about Bygg – I’ve been fortunate enough to find some time to do some actual implementation, and I now have a version of the tool that can do the following:
First, read a configuration of plugins to use during the build:
public class PluginConfiguration {
public static Plugins plugins() {
return new Plugins() {
public List plugins() {
return Arrays.asList(
new ArtifactVersion(ProjectArtifacts.BYGG_TEST_PLUGIN, "1.0-SNAPSHOT"),
new ArtifactVersion(ProjectArtifacts.GUICE, "2.0"));
}
};
}
}
Second, use that set of plugins to compile a project configuration:
public class Configuration {
public static ByggConfiguration configuration() {
return new ByggConfiguration() {
public TargetDAG getTargetDAG() {
return TargetDAG.DEFAULT
.add("plugin") // defines the target name when executing
.executor(new ByggTestPlugin()) // indicates what executing the target means
.requires("test") // means it won't be run until after "test"
.build();
}
};
}
}
Third, actually execute that build – although in the current version, none of the target executors have an actual implementation, so all they do is create a file with their name and the current time stamp under the target directory. The default build graph that is implemented contains targets that pretend to assemble the classpaths (placeholder for downloading any necessary dependencies) for the main code and the test code, targets that compile the main and test code, a target that runs the tests, and a target that pretends to create a package. As the sample code above hints, I’ve got three projects: Bygg itself, a dummy plugin, and a test project whose build requires the test plugin to be compiled and executed.
Fourth – with no example – cleaning up the target directory. This is the only feature that is fully implemented, being of course a trivial one. On my machine, running a clean in a tiny test project is 4-5 times faster using Bygg than Maven (taking 0.4 to 0.5 seconds of user time as compared to more than 2 for Maven), so thus far, I’m on target with regard to performance improvements. A little side note on cleaning is that I’ve come to the conclusion that clean isn’t a target. You’re never ever going to want to deploy a ‘clean’, or use it for anything. It’s an optional step that might be run before any actual target. To clarify that distinction, you specify targets using their names as command line arguments, but cleaning using -c or –clean:
bygg.sh -c compile plugin
As is immediately obvious, there’s a lot of rough edges here. The ones I know I will want to fix are:
- Using annotations (instead of naming conventions) and generics (for type safety) in the configuration classes – I’m compiling and loading the configuration files using a library called Janino, which has an API that I think is great, but which by default only supports Java 4. There’s a way around it, but it seems a little awkward, so I’m planning on stealing the API design and putting in a front for JavaCompiler instead.
- Updating the returned classes (Plugins and ByggConfiguration), as today they only contain a single element. Either they should be removed, or perhaps they will need to become a little more powerful.
- Changing the names of stuff – TargetDAG especially is not great.
- There’s a lot of noise, much of which is due to Java as a language, but some of which can probably be removed. The Plugins example above is 11 lines long, but only 2 lines contain useful information – and that’s not counting import statements, etc. Of course, since the number of ‘noise lines’ is pretty much constant, with realistically large builds, the signal to noise ratio will improve. Even so, I’d like it to be better.
- I’m pretty sure it’s a good idea to move away from saying “this target requires target X” to define the order of execution towards something more like “this target requires the compiled main sources”. But there may well be reasons why you would want to keep something like “requires” or “before” in there – for instance, you might want to generate a properties file with information collected from version control and CI system before packaging your artifact. Rather than changing the predefined ‘package’ target, you might want to just say ‘run this before package’ and leave the file sitting in the right place in the target directory. I’m not quite sure how best to deal with that case yet – there’s a bit more discussion of this a little later.
Anyway, all that should be done in the light of some better understanding of what is actually needed to build something. So before I continue with improving the API, I want to take a few more steps on the path of execution.
As I’ve mentioned in a previous post, a build configuration in Bygg is a DAG (Directed Acyclic Graph). A nice thing about that is that it opens up the possibility of executing independent paths on the DAG concurrently. Tim pointed out to me that that kind of concurrent execution is an established idea called Dataflow Concurrency. In Java terms, Dataflow Concurrency essentially boils down to communicating all shared mutable state via Futures (returned by Callables executing the various tasks). What’s interesting about the Bygg version of Dataflow Concurrency is that the ‘Dataflow Variables’ can and will be parameters of the Callables executing tasks, rather than being hard-coded as is typical in the Dataflow Concurrency examples I’ve seen. So the graph will exist as a data entity as opposed to being hardwired in the code. This means that deadlock detection is as simple as detecting cycles in the graph – and since there is a requirement that the build configuration must be a DAG, builds will be deadlock free. In general, I think the ability to easily visualise the exact shape of the DAG of a build is a very desirable thing in terms of making builds easily understandable, so that should probably be a priority when continuing to improve the build configuration API.
Another idea I had from the reference to dataflow programming is that the canonical example of dataflow programming is a spreadsheet, where an update in one cell trickles through into updates of other cells that contain formulas that refer to the first one. That example made me change my mind about how different targets should communicate their results to each other. Initially, I had been thinking that most of the data that needs to be passed on from one target to the next should be implicitly located in a well-defined location on disk. So the test compiler would leave the test classes in a known place where the test runner knows to look for them. But that means loading source files into memory to compile them, then writing the class files to disk, then loading them into memory again. That’s a lot of I/O, and I have the feeling that I/O is often one of the things that slows builds down the most. What if there would be a dataflow variable with the classes instead? I haven’t yet looked in detail at the JavaFileManager interface, but it seems to me that it would make it possible to add an in-memory layer in front of the file system (in fact, I think that kind of optimisation is a large part of the reason why it exists). So it could be a nice optimisation to make the compiler store files in memory for test runners, packagers, etc., to pick up without having to do I/O. There would probably have to be a target (or something else, maybe) that writes the class files to disk in parallel with the rest of the execution, since the class files are nice to have as an optimisation for the next build – only recompiling what is necessary. But that write doesn’t necessarily have to slow down the test execution. All that is of course optimisation, so the first version will just use a plain file system-based JavaFileManager implementation. Still, I think it is a good idea to only have a very limited number of targets that directly access the file system, in order to open up for that kind of optimisation. The remainder of the targets should not be aware of the exact structure of the target directory, and what data is stored there.
I’m hoping to soon be able to find some more time to try these ideas out in code. It’ll be interesting to see how hard it is to figure out a good way to combine abstracting away the ‘target’ directory with full freedom for plugins to add stuff to the build package and dataflow concurrency variables.
Bygg – Better Dependency Management
Posted by Petter Måhlén in Java on February 17, 2011
I’ve said before that the one thing that Maven does amazingly well is dependency management. This post is about how to do it better.
Declaring and Defining Dependencies
In Maven, you can declare dependencies using a <dependencyManagement /> section in either the current POM or some parent POM, and then use them – include them into the current build – using a <dependencies /> section. This is very useful because it allows you to define in a single place which version of some dependency should be used for a set of related modules. It looks something like:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.shopzilla.site2.service</groupId>
<artifactId>common</artifactId>
<version>${service.common.version}</version>
</dependency>
<dependency>
<groupId>com.shopzilla.site2.service</groupId>
<artifactId>common-web</artifactId>
<version>${service.common.version}</version>
</dependency>
<dependency>
<groupId>com.shopzilla.site2.core</groupId>
<artifactId>core</artifactId>
<version>${core.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.shopzilla.site2.service</groupId>
<artifactId>common</artifactId>
</dependency>
<dependency>
<groupId>com.shopzilla.site2.core</groupId>
<artifactId>core</artifactId>
</dependency>
</dependencies>
To me, there are a couple of problems here:
- Declaring a dependency looks pretty much identical to using one – the only difference is that the declaration is enclosed inside a <dependencyManagement /> section. This makes it hard to know what it is you’re looking at if you have a large number of dependencies – is this declaring a dependency or actually using it?
- It’s perfectly legal to add a <version/> tag in the plain <dependencies /> section, which will happen unless all the developers touching the POM a) understand the distinction between the two <dependencies /> sections, and b) are disciplined enough to maintain it.
For large POMs and POM hierarchies in particular, the way to define shared dependencies becomes not only overly verbose but also hard to keep track of. I think it could be made much easier and nicer in Bygg, something along these lines:
// Core API defined in Bygg proper
public interface Artifact {
String getGroupId();
String getArtifactId();
}
// ----------------------------------------------
// This enum is in some shared code somewhere - note that the pattern of declaring artifacts
// using an enum could be used within a module as well if desired. You could use different enums
// to define, for instance, sets of artifacts to use when talking to databases, or when developing
// a web user interface, or whatever.
public enum MyArtifacts implements Artifact {
SERVICE_COMMON("com.shopzilla.site2.service", "common"),
CORE("com.shopzilla.site2.core", "core");
JUNIT("junit", "junit");
}
// ----------------------------------------------
// This can be declared in some shared code as well, probably but not
// necessarily in the same place as the enum. Note that the type of
// the collection is Collection, indicating that it isn't ordered.
public static final Collection ARTIFACT_VERSIONS = ImmutableList.of(
new ArtifactVersion(SERVICE_COMMON, properties.get("service.common.version")),
new ArtifactVersion(CORE, properties.get("core.version")),
new ArtifactVersion(JUNIT, "4.8.1"));
// ----------------------------------------------
// In the module to be built, define how the declared dependencies are used.
// Here, ordering might be significant (it indicates the order of artifacts on the
// classpath - the reason for the 'might' is I'm not sure if this ordering can carry
// over into a packaged artifact like a WAR).
List moduleDependencies = ImmutableList.of(
new Dependency(SERVICE_COMMON, EnumSet.of(MAIN, PACKAGE)),
new Dependency(CORE, EnumSet.of(MAIN, PACKAGE)),
new Dependency(JUNIT, EnumSet.of(TEST)));
The combination of a Collection of ArtifactVersions and a List of Dependency:s is then used by the classpath assembler target to produce an actual classpath for use in compiling, running, etc. Although the example code shows the Dependency:s as a plain List, I kind of think that there may be value in not having the actual dependencies be something else. Wrapping the list in an intelligent object that gives you filtering options, etc., could possibly be useful, but it’s a bit premature to decide about that until there’s code that makes it concrete.
The main ideas in the example above are:
- Using enums for the artifact identifiers (groupId + artifactId) gives a more succinct and harder-to-misspell way to refer to artifacts in the rest of the build configuration. Since you’re editing this code in the IDE, finding out exactly what the artifact identifier means (groupId + artifactId) is as easy as clicking on it while pressing the right key.
- If the build configuration is done using regular Java code, shared configuration items can trivially be made available as Maven artifacts. That makes it easy to for instance have different predefined groups of related artifacts, and opens up for composed rather than inherited shared configurations. Very nice!
- In the last bit, where the artifacts are actually used in the build, there is an outline of something I think might be useful. I’ve used Maven heavily for years, and something I’ve never quite learned how they work is the scopes. It’s basically a list of strings (compile, test, provided, runtime) that describe where a certain artifact should be used. So ‘compile’ means that the artifact in question will be used when compiling the main source code, when running tests, when executing the artifact being built and (if it is a WAR), when creating the final package. I think it would be far simpler to have a set of flags indicating which classpaths the artifact should be included in. So MAIN means ‘when compiling and running the main source’, TEST is ditto for the test source, and PACKAGE is ‘include in the final package’, and so on. No need to memorise what some scope means, you can just look at the set of flags.
Another idea that I think would be useful is adding an optional Repository setting for an Artifact. With Maven, you can add repositories in addition to the default one (Maven Central at Ibiblio). You can have as many as you like, which is great for some artifacts that aren’t included in Maven Central. However, adding repositories means slowing down your build by a wide margin, as Maven will check each repository defined in the build for updates to each snapshot version of an artifact. Whenever I add a repository, I do that to get access to a specific artifact. Utilising that fact by having two kinds of repositories – global and artifact-specific, maybe – should be simple and represent a performance improvement.
Better Transitive Conflict Resolution
Maven allows you to not have to worry about transitive dependencies required by libraries you include. This is, as I’ve argued before, an incredibly powerful feature. But the thing is, sometimes you do need to worry about those transitive dependencies: when they introduce binary incompatibilities. A typical example is something I ran into the other day, where a top-level project used version 3.0.3 of some Spring jars (such as ‘spring-web’), while some shared libraries eventually included another version of Spring (the ‘spring’ artifact, version 2.5.6). Both of these jars contain a definition of org.springframework.web.context.ConfigurableWebApplicationContext, and they are incompatible. This leads to runtime problems (in other words, the problem is visible too late; it should be detected at build time), and the only way to figure that out is to recognise the symptoms of the problem as a “likely binary version mismatch”, then use mvn dependency:analyze to figure out possible candidates and add exclude rules like this to your POM:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.shopzilla.site2.service</groupId>
<artifactId>common</artifactId>
<version>${service.common.version}</version>
<exclusions>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.collections</groupId>
<artifactId>google-collections</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.shopzilla.site2.core</groupId>
<artifactId>core</artifactId>
<version>${core.version}</version>
<exclusions>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.collections</groupId>
<artifactId>google-collections</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</dependencyManagement>
As you can tell from the example (just a small part of the POM) that I pasted in, I had a similar problem with google-collections. The top level project uses Guava, so binary incompatible versions included by the dependencies needed to be excluded. The problems here are:
- It’s painful to figure out what libraries cause the conflicts – sometimes, you know or can easily guess (like the fact that different versions of Spring packages can clash), but other times you need to know something a little less obvious (like the fact that Guava has superseded google-collections, something not immediately clear from the names). The tool could just tell you that you have binary incompatibilities on your classpath (I actually submitted a patch to the Maven dependency plugin to fix that, but it’s been stalled for 6 months).
- Once you’ve figured out what causes the problem, it’s a pain to get rid of all the places it comes from. The main tool at hand is the dependency plugin, and the way to figure out where dependencies come from is mvn dependency:tree. This lets you know a single source of a particular dependency. So for me, I wanted to find out where the spring jar came from – that meant running mvn dependency:tree, adding an exclude, running it again to find where else the spring jar was included, adding another exclude, and so on. This could be so much easier. And since it could be easier, it should be.
- What’s more, the problems are sometimes environment-dependent, so you’re not guaranteed that they will show up on your development machine. I’m not sure about the exact reasons, but I believe that there are differences in the order in which different class loaders load classes in a WAR. This might mean that the only place you can test if a particular problem is solved or not is your CI server, or some other environment, which again adds pain to the process.
- The configuration is rather verbose and you need to introduce duplicates, which makes your build files harder to understand at a glance.
Apart from considering binary incompatibilities to be errors (and reporting on exactly where they are found), here’s how I think exclusions should work in Bygg:
dependencies.exclude().group("com.google.collections").artifact("google-collections")
.exclude().group("org.springframework").artifact("spring.*").version(except("3.0.3"));
Key points above are:
- Making excludes a global thing, not a per-dependency thing. As soon as I’ve identified that I don’t want spring.jar version 2.5.6 in my project, I know I don’t want it from anywhere at all. I don’t care where it comes from, I just don’t want it there! I suppose there is a case for saying “I trust the core library to include google-collections for me, but not the common-web one”, so maybe global excludes aren’t enough. But they would certainly have helped me tremendously a lot of the times I’ve had to use Maven exclusions, and I can’t think of a case where I’ve actually wanted specifically to have an artifact-specific exclusion.
- Defining exlusion filters using a fluent API that includes regular expressions. With Spring in particular, you want to make sure that all your jars have the same version. It would be great to be able to say that you don’t want anything other than that.
Build Java with Java?!
I’ve gone through different phases when thinking about using Java to configure builds rather than XML. First, I thought “it’s great, because it allows you to more easily use the standard debugger for the builds and thereby resolve Maven’s huge documentation problem”. But then I realised that the debugging is enabled by ensuring that the IDE has access to the source code of the build tool and plugins that execute the build, and that how you configure it is irrelevant. So then I thought that using Java to configure is pretty good anyway, because it means developers won’t need to learn a new language (as with Buildr or Raven), and that IDE integration is a lot easier. The IDE you use for your regular Java programming wouldn’t need to be taught anything specific to deal with some more Java code. I’ve now come to the conclusion that DSL-style configuration APIs, and even more, using the standard engineering principles for sharing and reusing code for build configurations is another powerful argument in favour of using Java in the build configuration. So I’ve gone from “Java configuration is key”, to “Java configuration is OK, but not important” to “Java configuration is powerful”.
Bygg – Ideas for a Better Maven
Posted by Petter Måhlén in Java on January 24, 2011
In a previous post, I outlined some objectives for a better Maven. In this post, I want to talk about some ideas for how to achieve those objectives.
Build Java with Java
The first idea is that the default modus operandi should be that builds are runnable as a regular Java application from inside the IDE, just like the application that is being built. The IDE integration of the build tool should ensure that source code for the build tool and its core plugins is attached so that the developer can navigate through the build tool source. A not quite necessary part of this is that build configuration should be done using Java rather than XML, Ruby, or something else. This gives the following benefits:
- Troubleshooting the build is as easy as just starting it in the debugger and setting break points. To understand how to use a plugin, you can navigate to the source implementing it from your build configuration. I think this is potentially incredibly valuable. If it is possible to integrate with IDEs to such an extent that the full source code of the libraries and plugins that are used in the build is available, that means that stepping through and debugging builds is as easy as for any library used in the product being built. And harnessing the highly trained skills that most Java developers have developed for understanding how a third-party library works is something that should make the build system much more accessible compared to having to rely on documentation.
- It can safely be assumed that Java developers are or at least want to be very proficient in Java. Using a real programming language for build configurations is very advantageous compared to using XML, especially for those occasions when you have to customise your build a little extra. (This should be the exception rather than the rule as it increases the risk of feature creep and reduces standardisation.)
- The IDEs that Java developers use can be expected to be great tools for writing Java code. Code completion, Javadoc popups, instant navigation to the source that implements a feature, etc. This should reduce the complexity of IDE integration.
- It opens up for very readable DSL-style APIs, which should reduce the build script complexity and increase succinctness. Also, using Java means you could instantly see which configuration options are available for the thing you’re tweaking at the moment (through method completion, checking values of enums, etc., etc.).
There are some drawbacks, such as having to figure out a way to bootstrap the build (the build configuration needs to be compiled before a build can be run), and the fact that you have to provide a command-line tool anyway for continuous integration, etc. But I don’t think those problems are hard enough to be significant.
I first thought of the idea of using Java for the build configuration files, and that that would be great. But as I’ve been thinking about it, I’ve concluded that the exact format of the configuration files is less important than making sure that developers can navigate through the build source code in exactly the same way as through any third party library. That is something I’ve wanted to do many times when having problems with Maven builds, but it’s practically impossible today. There’s no reason why it should be harder to troubleshoot your build than your application.
Interlude: Aspects of Build Configurations
Identifying and separating things that need to be distinct and treated differently is one of the hard things to do when designing any program, and one of the things that has truly great effect if you get it right. So far, I’ve come up with a few different aspects of a build, namely:
- The project or artifact properties – this includes things such as the artifact id, group id, version etc., and can also include useful information such as a project description, SCM links, etc.
- The project’s dependencies – the third-party libraries that are needed in the build; either at compile time, test time or package time.
- The build properties – any variables that you have in your build. A lot of times, you want to be able to have environment-specific variables that you use, or to refer to build-specific variables such as the output directory for compiled classes. The distinction between variables that may be overridden on a per-installation basis from variables that are determined during the build may mean that there are more than one kind of properties.
- The steps that are taken to complete the build – compilations, copying, zipping, running tests, and so on.
- The things that execute the various steps – the compiler, the test executor, a plugin that helps generate code from some type of resources, etc.
The point of separating these aspects of the build configuration is that it is likely that you’ll want to treat them differently. In Maven, almost everything is done in a single POM file, which grows large and hard to get an overview of, and/or in a settings.xml file that adds obscurity and reduces build portability. An example of a problem with bunching all the build configuration data into a single file is IntelliJ’s excellent Maven plugin, which wants to reimport the pom.xml with every change you make. Reimporting takes a lot of time on my chronically overloaded Macbook (well, 5-15 seconds, I guess – far too much time). It’s necessary because if I’ve changed the dependencies, IntelliJ needs to update its classpath. The thing is, I think more than 50% or even 70% of the changes I make to pom files don’t affect the dependencies. If the dependencies section were separate from the rest of the build configuration, reimporting could be done only when actually needed.
I don’t think this analysis has landed yet, it feels like some pieces or nuances are still missing. But it helps as background for the rest of the ideas outlined in this post. The steps taken during the build, and the order in which they should be taken, are separate from the things that do something during each step.
Non-linear Build Execution
The second idea is an old one: abandoning Maven’s linear build lifecycle and instead getting back to the way that make does things (which is also Ant’s way). So rather than having loads of predefined steps in the build, it’s much better to be able to specify a DAG of dependencies between steps that defines the order of execution. This is better for at least two reasons: first, it’s much easier to understand the order of execution if you say “do A before B” or “do B after A” in your build configuration than if you say “do A during the process-classes phase and B during the generate-test-sources phase”. And second, it opens up the door to do independent tasks in parallel, which in turn creates opportunities for performance improvements. So for instance, it could be possible to download dependencies for the test code in parallel with the compilation of the production code, and it should be possible to zip up the source code JAR file at the same time as JavaDocs are generated.
What this means in concrete terms is that you would write something like this in your build configuration file:
buildSteps.add(step("copyPropertiesTemplate")
.executor(new CopyFile("src/main/template/properties.template",
"${OUTPUT_DIR}/properties.txt"))
.before("package"));
Selecting what to build would be done via the build step names – so if all you wanted to do was to copy the properties template file, you would pass “copyPropertiesTemplate” to the build. The tool would look through the build configuration and in this case probably realise that nothing needs to be run before that step, so the “copyPropertiesTemplate” step would be all that was executed. If, on the other hand, the user stated that the “package” step should be executed, the build tool would discover that lots of things have to be done before – not only “copyPropertiesTemplate” but also “performCoverageChecks”, which in turn requires “executeTests”, and so on.
As the example shows, I would like to add a feature to the make/Ant version: specifying that a certain build step should happen before another one. The reason is that I think that the build tool should come with a default set of build steps that allow the most common build tasks to be run with zero configuration (see below for more on that). So you should always be able to say “compile”, or “test”, and that should just work as long as you stick the the conventions for where you store your source code, your tests, etc. This makes it awkward for a user to define a build step like the one above in isolation, and then after that have to modify the pre-existing “package” step to depend on the “copyPropertiesTemplate” one.
In design terms, there would have to be some sort of BuildStep entity that has a unique name (for the user interface), a set of predecessors and successors, and something that should be executed. There will also have to be a scheduler that can figure out a good order to execute steps in. I’ve made some skeleton implementations of this, and it feels like a good solution that is reasonably easy to get right. One thing I’ve not made up my mind about is the name of this entity – the two main candidates are BuildStep and Target. Build step explains well what it is from the perspective of the build tool, while Target reminds you of Ant and Make and focuses the attention on the fact that it is something a user can request the tool to do. I’ll use build step for the remainder of this post, but I’m kind of thinking that target might be a better name.
Gradual Buildup of DI Scope
Build steps will need to communicate results to one another. Some of this will of necessity be done via the file system – for instance, the compilation step will leave class files in a well-defined place for the test execution and packaging steps to pick up. Other results should be communicated in-memory, such as the current set of build properties and values, or the exact classpath to be used during compilation. The latter should be the output of some assembleClassPath step that checks or downloads dependencies and provides an exact list of JAR files and directories to be used by the compiler. You don’t want to store that sort of thing on the file system.
In-memory parameters should be injected into the executors of subsequent build steps that need them. This means that the build step executors will be gradually adding stuff to the set of objects that can be injected into later executors. A concrete implementation of this that I have been experimenting with is using hierarchical Guice injectors to track this. That means that each step of the build returns a (possibly empty) Guice module, which is then used to create an injector that inherits all the previous bindings from preceding steps. I think that works reasonably well in a linear context, but that merging injectors in a more complex build scenario is harder. A possibly better solution is to use the full set of modules used and created by previous steps to create a completely new injector at the start of each build step. Merging is then simply taking the union of the sets of modules used by the two merging paths through the DAG.
This idea bears some resemblance to the concept of dynamic dependency injection, but it is different in that there are parallel contexts (one for each concurrently executing path) that are mutating as each build step is executed.
I much prefer using DI to inject dependencies into plugins or build steps over exposing the entire project configuration + state to plugins, for all the usual reasons. It’s a bit hard to get right from a framework perspective, but I think it should help simplify the plugins and keep them isolated from one another.
Core Build Components Provided
One thing that Maven does really well is to support simple builds. The minimal pom is really very tiny. I think this is great both in terms of usability and as an indication of powerful build standardisation/strong conventions. In the design outlined in this post, the things that would have to come pre-configured with useful defaults are a set of build steps with correct dependencies and associated executors. So there would be a step that assembles the classpath for the main compilation, another one that assembles the classpath for the test compilation, yet another one that assembles the classpath for the test execution and probably even one that assembles the classpath to be used in the final package. These steps would probably all make use of a shared entity that knows how to assemble classpaths, and that is configured to know about a set of repositories from which it can download dependencies.
By default, the classpath assembler would know about one or a few core repositories (ibiblio.org for sure). Most commercial users will hopefully have their own internal Maven repositories, so it needs to be possible to tell the classpath assembler about these. Similarly, the compiler should have some useful defaults for source version, file encodings, etc., but they should be possible to override in a single place and then apply to all steps that use them.
Of course, the executors (classpath assembler, compiler, etc.) would be shared by build steps by default, but they shouldn’t necessarily be singletons – if one wanted to compile the test code using a different set of compiler flags, one could configure the build to have two compiler instances with different parameters.
The core set of build steps and executors should at a minimum allow you to build, test and deploy (in the Maven sense) a JAR library. Probably, there should be more stuff that is considered to be core than just that.
Naming the Tool
The final idea is a name – Bygg. Bygg is a Swedish word that means “build” as in “build X!”, not as in “a build” or “to build” (a verb in imperative form in other words). It’s probably one letter too long, but at least it’s not too hard to type the second ‘g’ when you’ve already typed the first. It’s got the right number of syllables and it means the right thing. It’s even relatively easy to pronounce if you know English (make it sound like “big” and you’ll be fine), although of course you have to have Scandinavian background to really pronounce the “y” right.
That’s more than enough word count for this post. I have some more ideas about dependency management, APIs and flows in the tool, but I’ll have to save them for another time. Feel free to comment on these ideas, particularly about areas where I am missing the mark!
Objectives for A Better Maven
Posted by Petter Måhlén in Software Development on January 20, 2011
My friend Josh Slack made me aware of this post, by a guy (Kent Spillner) who is totally against Maven in almost every way. As I’ve mentioned before, I think Maven is the best tool out there for Java builds, so of course I like it better than Kent does. Still, there’s no doubt he has some points that you can’t help agreeing with. Reading his post made me think (once again) about what is great and not so great about Maven, and also of some ideas about how to fix the problems whilst retaining the great stuff (edit: I’ve started outlining these ideas here, with more to follow).
First, some of the things that are great:
- Dependency Management – I would go so far as to argue that Maven has done more to enable code reuse than anything else that is touted as a ‘reusability paradigm’ (such as OO itself). Before Maven and its repositories, you had to manually add every single dependency and their transitive requirements into each project, typically even into your source repository. The amount of manual effort to upgrade from one version of a library, and its transitive dependencies, means the optimal size of a library is quite large, making them unfocused and bloated. What’s more, it also means that library designers have a strong need to reduce the number of things they allow themselves to depend on, which reduces the scope for code reuse. With Maven, libraries can be more focused as it is effortless to have a deep dependency tree. At Shopzilla, our top-level builds typically include 50-200 dependencies. Imagine adding these to your source repository and keeping them up to date with every change – completely impossible!
- Build standardisation. The first sentence in Kent Spillner’s post is “The best build tool is the one you write yourself”. That’s probably true from the perspective of a single project, but with a larger set of projects that are collaboratively owned by multiple teams of developers, that idea breaks quickly. Again, I’ll use Shopzilla as an example – we have more than 100 Git repositories with Java code that are co-owned by 5-6 different teams. This means we must have standardised builds, or we would waste lots of time due to having to learn about custom builds for each project. Any open source project exists in an even larger ecosystem; essentially a global one. So unless you know that the number of developers who will be building your project is always going to be small, and that these developers will only have to work with a small number of projects, your build should be “mostly declarative” and as standardised as you can make it.
- The wealth of plugins that allow you to do almost any build-related task. This is thanks to the focus on a plugin-based architecture right from the get-go.
- The close integration with IDEs that makes it easier (though not quite painless) to work with it.
Any tool that would improve on Maven has to at least do equally well on those four counts.
To get a picture of the opportunities for improvement, here’s my list of Maven major pain points:
- Troubleshooting is usually hard to extremely hard. When something breaks, you get very little help from Maven to figure out what it is. Enabling debug level logging on the build makes it verbose to the point of obscuring the error. If you, like me, like to use the source code to find out what is happening, it is difficult to find because you will have to jump from plugin to plugin, and most plugins have different source repositories.
- Even though there is a wealth of plugins that allow you to do almost anything, it is usually unreasonably hard to a) find the right plugin and b) figure out how to use it. Understanding what Maven and its plugins do is really hard, and the documentation is frequently sub-standard.
- A common complaint is the verbose XML configuration. That is definitely an issue, succinctness improves readability and ease of use.
- The main drawback of the transitive dependency management is the risk of getting incompatible versions of the same library, or even worse, class. There is very little built-in support for managing this problem in Maven (there is some in the dependency plugin, but actually using that is laborious). This means that it is not uncommon to have large numbers of ‘exclusion’ tags for some dependencies polluting your build files, and that you anyway tend to have lots of stuff that you never use in your builds.
- Maven is slow, there’s no doubt about that. It takes time to create various JVMs, to download files/check for updates, etc. Also, every build runs through the same build steps even if some of them are not needed.
- Builds can succeed or fail on different machines for unobvious reasons – typically, the problem is due to differing versions of SNAPSHOT dependencies being installed in the local repository cache. It can also be due to using different versions of Maven plugins.
There’s actually quite a lot more that could be improved, but those are probably my main gripes. When listing them like this, I’m surprised to note that despite all these issues, I still think Maven is the best Java build tool out there. I really do think it is the best, but there’s no doubt that there’s plenty of room to improve things. So I’ve found myself thinking about how I would go about building a better Maven. I am not sure if I’ll be able to actually find the time to implement it, but it is fascinating enough that I can’t let go of the idea. Here’s what I would consider a useful set of objectives for an improved Maven, in order of importance:
- Perfect interoperability with the existing Maven artifact management repository infrastructure. There is so much power and value in being able to with near-zero effort get access to pretty much any open source project in the Java world that it is vital to be able to tap into that. Note that the value isn’t just in managing dependencies in a similar way to how Maven does it, but actually reusing the currently available artifacts and repositories.
- Simplified troubleshooting. More and better consistency checks of various kinds and at earlier stages of the build. Better and more to the point reporting of problems. Great frameworks tend to make this a key part of the architecture from the get-go rather than add it on as an afterthought.
- A pluggable architecture that makes it easy to add custom build actions. This is one of Maven’s great success points so a new framework has to be at least as good. I think it could and should be even easier than Maven makes it.
- Encouraging but not enforcing standardised builds. This means sticking to the idea of “convention over configuration“. It also means that defining your build should be a “mostly declarative” thing, not an imperative thing. You should say “I want a JAR”, not “zip up the class files in directory X”. Programming your builds is sometimes a necessary evil so it must be possible, but it should be discouraged as it is a slippery slope that leads to non-standardised builds, which in turn means making it harder for anybody coming new to a project to get going with it.
- Great integration with IDEs, or at least support for the ability to create great integration with IDEs. This is a necessary part of giving programmers a workflow that never forces them out of the zone.
- Less verbose configuration. Not a show-stopper in my opinion, but definitely a good thing to improve.
- EDIT: While writing further posts on this topic, I’ve realised that there is one more thing that I consider very important: improving performance. Waiting for builds is a productivity-killing drag.
It’s good to specify what you want to do, but in some ways, it’s even better to specify things you’re not trying to achieve either because they’re not relevant or because you find them counter-productive. That gives a different kind of clarity. So here’s a couple of non-objectives:
- Using the same artifact management mechanism for build tool plugins as for project dependencies, the way Maven does. While there is some elegance to this idea, it also comes with a host of difficulties – unreproducible builds being the main one, and while earlier versions of Maven actively updated plugin versions most or all the time, Maven 3 now issues warnings if you haven’t specified the plugin versions for your build.
- Reimplementing all the features provided by Maven plugins. Obviously, trying to out-feature something so feature-rich as Maven would be impossible and limit the likelihood of success hugely. So one thing to do is to select a subset of build steps that represent the most common and/or most different things that are typically done in a build and then see how well the framework deals with that.
- Being compatible with Maven plugins. In a way, it would be great to be able for a new build tool to be able to use any existing Maven plugin. But being able to do that would limit the architectural options and increase the complexity of the new architecture to the point of making it unlikely to succeed.
- Reproducing the ‘project information’ as a core part of the new tool. Producing project information was one of the core goals of Maven when it was first created. I personally find that less than useful, and therefore not worth making into a core part of a better Maven. It should of course be easy to create a plugin that does this, but it doesn’t have to be a core feature.
I’ve got some ideas for how to build a build tool that meets or is likely to meet most of those objectives. But this post is already more than long enough, and I’d anyway like to stop here to ask for some feedback. Any opinions on the strengths, weaknesses and objectives outlined here?
Testing and Code Correctness
Posted by Petter Måhlén in Software Development on December 10, 2010
Lately, I’ve found myself disagreeing with such giants as Trygve Reenskaug and Tony Hoare, and thinking that I have understood something about software that maybe they have not. A nobody disagreeing with two famous professors! Can I have a point? Well, read on and make up your own mind about it.
Since discovering about Trygve’s brainchild DCI, I’ve been following the discussions on the Object Composition discussion group. I’m not participating actively in the discussions; the main reason for me following the group is that Trygve is active there, and he has a lot of profound insights into software development which makes reading his posts a joy. But I’ve found myself disagreeing with him on one or possibly two closely related points. In at least one of his talks, he makes the point that testing does not help you get quality into a product. All tests do is prove that a particular execution path with particular parameter values works, they say nothing about what will happen if some parameter values change, and no matter how much you test some code, you can’t say that it is bug-free. Instead, the way to get quality into code is through readability. He often quotes Tony Hoare, who said:
“There are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies and the other is to make it so complicated that there are no obvious deficiencies.”
This is a lovely and memorable quote, but as all soundbites, it is a simplification. In fact, I think it is simplified to the point of not being meaningful, and while I think that Trygve’s point about testing is correct, I also think it is not very important and a slightly dangerous point to make as it might discourage you from testing. Tests, especially automated ones, are critical when building quality software, even though they don’t put quality into the product. Let me start on why I don’t think Tony Hoare’s quote is great with two code examples.
Some code that works
public class Multiplier {
private static final double POINT_25 = 0.25;
public double multiplyByPoint25(double amount) {
return amount * POINT_25;
}
}
This code is simple, to the point where it obviously contains no deficiencies. It’s not particularly interesting, but a glance shows that it does what you’d expect it to. One point to Tony!
Some code that is broken
public class VatCalculator {
private static final double VAT_RATE = 0.25;
public double calculateVat(double amount) {
return amount * VAT_RATE;
}
}
This code is broken in at least two ways:
- It does monetary calculations using floating-point arithmetic. This means that calculations aren’t exact, and exactness is always a requirement when dealing with money (see for instance Effective Java, Item 48 for more on this).
- It is probably broken in more subtle ways as well. In Sweden, the default VAT rate is indeed 25% on top of the price before VAT. But most of the time, people in Sweden think about this backwards – the only price they see is the one with VAT, so some people prefer to multiply the total price by .2 to get the part of the total price that is VAT. We don’t know if the amount is the amount before VAT or the total amount including VAT. Also, the VAT rate depends on the item type, so if this method were called using the price of a pencil, it would probably give the right answer, but it wouldn’t for a book. And if the amount is the total of an order for a pencil and a book, it’s wrong in yet another way. The list of things that could be broken in terms of how to do VAT calculations goes on.
And the funny thing is, from a machine-instructions perspective, the two classes are of course identical! Why is the first one right, and the second one wrong, just because we changed some names? When the names changed, our perception of the programmer’s intent changed with them. Suddenly, the identical machine instructions have a more specific purpose, and we see more of the actual or probable business rules that should be applied. This makes the second version obviously broken because it uses floating-point arithmetic for monetary calculations. We understand enough about the programmer’s intent to find a mistake. But while the floating-point error is obvious, there is nothing in the code that gives us clear evidence as to whether the VAT calculation is correct in terms of the rate that is being applied or not.
Clearly, readability is not sufficient to guarantee correctness. Correct code meets its business requirements – the intent of the person who uses it for something. Readability can at best tell us if it meets the intent of the programmer that wrote it. This doesn’t mean readability is unimportant; on the contrary, readable code is a holy grail to be strived for at almost all cost. But it does mean that Tony Hoare’s goal is unachievable. The code by itself cannot “obviously have no deficiencies”, because the code only tells us what it does, not what it should do.
Testing to the Rescue
So how can we ensure that our code is correct? Well, we need well-defined requirements and the ability to match those requirements with what the code does. There are people whose full-time job is to define requirements; all they do is to formulate business users’ descriptions of what they do in terms that should be unambiguous, free of duplication, conflicts, and so on, so that programmers and testers can get a clear picture of what the code should actually be doing. There are whole toolsets for requirements analysis and management that help these people produce consistent and unambiguous definitions of requirements. Once that’s done the problem is of course that it’s really hard to know if your code actually meet all the requirements that are defined. No problem, there’s further tools and processes that support mapping the requirements to test cases, executions of these test cases and the defects found and fixed.
Like many others (this is at the heart of agile), I think all that is largely a waste of time. I’m not saying it doesn’t help, it’s just very inefficient. It’s practically impossible to formulate anything using natural language in a way that is unambiguous, consistent and understandable. And then mapping requirements defined using natural language to tests and test executions is again hard to the point of being impossible. The only languages we have that allow us to formulate statements unambiguously and with precision are formal systems such as programming languages. But wait, did I just say we can write something that has no ambiguity in code? Could we formulate our requirements using code? Yes, of course. Done right, that’s exactly what automated tests are.
If our automated tests reflect the intent of the users of the code, we can get an extremely detailed and precise specification of the requirements that has practically zero cost of verification. Since the specification is written in a programming language, it is written using one of the best tools we know how to design in terms of optimal unambiguity and readability. As we all know, programming languages have shortcomings there, but they are way superior to natural language.
The argument that business users won’t be able to understand tests/requirements written in code and that they therefore must be in natural language is easy to refute on two grounds: first, business users don’t understand a Word document or database with hundreds or thousands of requirements either (and neither do programmers), and second, let the code speak for itself. Business users can and do understand what your product does, and if it does the wrong thing, they can tell you. Fix the code (tests first), and ship a new version. Again, a core principle in agile.
I often come across a sentiment among developers that tests are restrictive (“I’ve fixed the code, why do I have to fix the test too”), or that you “haven’t got the time to write tests”. That’s a misunderstanding – done right, tests are liberating and save time. Liberating, because the fact that your tests specify how the code is intended to behave means that you don’t need to worry as much about breaking existing functionality. That enables you to have multiple teams co-owning the same code, which improves your agility. Maybe even more importantly, having a robust harness of tests around some code enables you to refactor it and thereby keep the code readable even in the face of evolution of the feature set it must support.
So that should hopefully explain why I think the point that Trygve made about tests not being able to get quality into a product is valid but not really important. The quality comes from the clarity of the system architecture, system design and code implementation, not from the tests. But automated tests enable you to keep quality in a product as it evolves by preventing regression errors and making it possible for you to keep the all-important clarity and readability up to date even as the code evolves.
The Power of Standardisation
Posted by Petter Måhlén in Software Development on December 2, 2010
A couple of recent events made me see the value of company-internal standardisation in a way that I hadn’t before. Obviously, reusing standardised solutions for software development is a good thing, as it is easier to understand them. But I’ve always rated continuous evolution of your technologies and choosing the best tool for the problem at hand higher. I’m beginning to think that was wrong, and that company-internal standards are or can be a very important consideration when choosing solutions.
Let’s get to the examples. First, we’ve had a set of automated functional regression tests that we can run against our sites for quite some time. But since the guy who developed those tests left, it has turned out that we can’t run them any more. The reason is that they were developed using Perl, a programming language that most of the team members are not very comfortable with, and that the way you would run them involved making some manual modifications to certain configuration files, then selecting the right ‘main’ file to execute. We’ve recently started replacing those tests with new ones written in Java and controlled by TestNG. This means it was trivial for us to run the tests through Maven. Some slight cleverness (quite possibly a topic for another blog post) allows us to run the tests for different combinations of sites (our team runs 8 different sites with similar but not identical functionality) and browsers using commands like this:
mvn test -Pall-sites -Pfirefox -Pchrome -Pstage
This meant it was trivial to get Hudson to run these tests for us against the staging environment and that both developers and QA can run the tests at any time.
The second example is also related to automated testing – we’ve started creating a new framework for managing our performance tests. We’ve come to the conclusion that our team in the EU has different needs to the team in the US that maintains our current framework, and in the interest of perfect agility, we should be able to improve our productivity by owning the tools we work with. We just deployed the first couple of versions of that tool, and our QA Lead immediately told me that he felt that even though the tool is still far inferior to the one it will eventually replace, he was really happy to have a plain Java service to deploy as opposed to the current Perl/CGI-based framework. Since Java services are our bread and butter at Shopzilla (I’ve lost count, but our systems probably include about 30-50 services, most of which are written in Java and use almost RESTful HTTP+XML APIs), we have great tools that support automated deployment and monitoring of these services.
The final example was a program for batch processing of files that we need for a new feature. Our initial solution was a plain Java executable that monitored a set of directories for files to process. However, it quickly became obvious that we didn’t know how to deal with that from a configuration management/system operations perspective. So even though the development and QA was done, and the program worked, we decided to refit it as one of our standard Java services, with a feature to upload files via POST requests instead of monitoring directories.
In all of these cases, there are a few things that come to mind:
- We’ve invested a lot in creating tools and processes around managing Java services that are deployed as WARs into Tomcat. Doing that is dead easy for us.
- We get a lot of common features for free when reusing this deployment form: standard solutions for setting server-specific configuration parameters, logging, load balancing, debugging, build numbers, etc.
- Every single person working here is familiar with our standard Java/Tomcat services. Developers know where to find the source code and where the entry points are. QA knows where to find log files, how to deploy builds for testing and how to check the current configuration. CM knows how to configure environments and how to set up monitoring tools, and so on.
I think there is a tendency among developers – certainly with me – to think only about their own part when choosing the tools and technologies for developing something new. So if I would be an expert in, say, Ruby on Rails, it would probably be very easy for me to create some kind of database admin tool using that. But everybody else would struggle with figuring out how to deal with it – where can I find the logs, how do I build it, how is it deployed and how do I set up monitoring?
There is definitely a tradeoff to be made between being productive today with existing tools and technologies and being productive tomorrow through migrating to newer and better ones. I think I’ve not had enough understanding of how much smoother the path can be if you stay with the standard solutions compared to introducing new technologies. My preference has always been to do gradual, almost continuous migration to newer tools and technologies, to the point of having that as an explicit strategy at Jadestone a few years ago. I am now beginning to think it’s quite possible that it is better to do technology migrations as larger, more discrete events where a whole ecosystem is changed or created at the same time. In the three cases above, we’re staying on old, familiar territory. That’s the path of least resistance and most bang for the buck.
DCI Better with DI?
Posted by Petter Måhlén in Software Development on October 2, 2010
I recently posted some thoughts about DCI and although I mostly thought it was great, I had two points of criticism in how it was presented: first, that using static class composition was broken from a layering perspective and second, that it seemed like class composition in general could be replaced by dependency injection. Despite getting a fair amount of feedback on the post, I never felt that those claims were properly refuted, which I took as an indication that I was probably right. But, although I felt and still feel confident that I am right about the claim about static class composition and layering, I was and am less sure about the second one. There was this distinction being made between class-oriented and object-oriented programming that I wasn’t sure I understood. So I decided to follow James Coplien’s advice that I should read up on Trygve Reenskaug’s work in addition to his own. Maybe that way I could understand if there was a more subtle distinction between objects and classes than the one I called trivial in my post.
Having done that, my conclusion is that I had already understood about objects, and the distinction is indeed that which I called trivial. So no epiphany there. But what was great was that I did understand two new things. The first was something that Jodi Moran, a former colleague, mentioned more or less in passing. She said something like “DI (Dependency Injection) is of course useful as it separates the way you wire up your objects from the logic that they implement”. I had to file that away for future reference as I only understood it partially at the time – it sounded right, but what, exactly, were the benefits of separating out the object graph configuration from the business logic? Now, two years down the line, and thanks to DCI, I think I fully get what she meant, and I even think I can explain it. The second new thing I understood was that there is a benefit of injecting algorithms into objects (DCI proper) as opposed to injecting objects into algorithms (DCI/DI). Let’s start with the point about separating your wiring up code from your business logic.
An Example
Explanations are always easier to follow if they are concrete, so here’s an example. Suppose we’re working with a web site that is a shop of some kind, and that we’re running this site in different locations across the world. The European site delivers stuff all over Europe, and the one based in Wisconsin (to take some random US state) sells stuff all over but not outside the US. And let’s say that when a customer has selected some items, there’s a step before displaying the order for confirmation when we calculate the final cost:
// omitting interface details for brevity
public interface VatCalculator { }
public interface Shipper { }
public class OrderProcessor {
public void finaliseOrder(Order order) {
vatCalculator.addVat(order);
shipper.addShippingCosts(order);
// ... probably other stuff as well
}
}
Let’s add some requirements about VAT calculations:
- In the US, VAT is based on the state where you send stuff from, and Wisconsin applies the same flat VAT rate to any item that is sold.
- In the EU, you need to apply the VAT rules in the country of the buyer, and:
- In Sweden, there are two different VAT rates: one for books, and another for anything else.
- In Poland, some items incur a special “luxury goods VAT” in addition to the regular VAT. These two taxes need to be tracked in different accounts in the bookkeeping, so must be different posts in the order.
VAT calculations in the above countries may or may not work a little bit like that, but that’s not very relevant. The point is just to introduce some realistic complexity into the business logic.
Here’s a couple of classes that sketch implementations of the above rules:
public class WisconsinVAT implements VAT {
public void addVat(Order order) {
order.addVat(RATE * order.getTotalAmount(), "VAT");
}
}
public class SwedenVAT implements VAT {
public void addVat(Order order) {
Money bookAmount = sumOfBookAmounts(order.getItems());
Money nonBookAmount = order.getTotalAmount() - bookAmount)
order.addVat(BOOK_RATE * bookAmount + RATE * nonBookAmount, "Moms");
}
}
public class PolandVAT implements VAT {
public void addVat(Order order) {
Money luxuryAmount = sumOfLuxuryGoodsAmounts(order.getItems());
// Two VAT lines on this order
order.addVat(RATE * order.getTotalAmount(), "Podatek VAT");
order.addVat(LUXURY_RATE * luxuryAmount, "Podatek akcyzowy");
}
}
Right – armed with this example, let’s see how we can implement it without DI, with traditional DI and with DCI/DI.
VAT Calculation Before DI
This is a possible implementation of the OrderProcessor and VAT calculator without using dependency injection:
public class OrderProcessor {
private VatCalculator vatCalculator = new VatCalculatorImpl();
private Shipper shipper = new ShipperImpl();
public void finaliseOrder(Order order) {
vatCalculator.addVat(order);
shipper.addShippingCosts(order);
// ... probably other stuff as well
}
}
public class VatCalculatorImpl implements VatCalculator {
private WisconsinVAT wisconsinVAT = new WisconsinVAT();
private Map<Country, VAT> euVATs = new HashMap<>();
public VatCalculator() {
euVATs.put(SWEDEN, new SwedenVAT());
euVATs.put(POLAND, new PolandVAT());
}
public void addVat(Order order) {
switch (GlobalConfig.getSiteLocation()) {
case US:
wisconsinVAT.addVat(order);
break;
case EUROPE:
VAT actualVAT = euVATs.get(order.getCustomerCountry());
actualVAT.addVat(order);
}
}
}
The same classes that implement the business logic also instantiate their collaborators, and the VatCalculatorImpl accesses a singleton implemented using a public static method (GlobalConfig).
The main problems with this approach are:
- Only leaf nodes (yes, the use of the term ‘leaf’ is sloppy when talking about a directed graph – ‘sinks’ is probably more correct) are unit testable in practice. So while it’s easy to instantiate and test the PolandVAT class, instantiating a VatCalculator forces the instantiation of four other classes: all the VAT implementations plus the GlobalConfig, which makes testing awkward. Nobody describes these problems better than Miško Hevery, see for instance this post. Oh, and unit testing is essential not primarily as a quality improvement measure, but for productivity and as a way to enable many teams to work on the same code.
- As Trygve Reenskaug describes, it is in practice impossible to look at the code and figure out how objects are interconnected. Nowhere in the OrderProcessor is there any indication that it not only will eventually access the GlobalConfig singleton, but also needs the getSiteLocation() method to return a useful value, and so on.
- There is no flexibility to use polymorphism and swap implementations depending on the situation, making the code less reusable.The OrderProcessor algorithm is actually general enough that it doesn’t care exactly how VAT is calculated, but this doesn’t matter since the wiring up of the object graph is intermixed with the business logic. So there is no easy way to change the wiring without also risking inadvertent change to the business logic, and if we would want to launch sites in for instance African or Asian countries with different rules, we might be in trouble.
- A weaker argument, or at least one I am less sure of, is: because the object graph contains all the possible execution paths in the application, automated functional testing is nearly impossible. Even for this small, simple example, most of the graph isn’t in fact touched by a particular use case.
Countering those problems is a large part of the rationale for using Dependency Injection.
VAT Calculation with DI
Here’s what an implementation could look like if Dependency Injection is used.
public class OrderProcessor {
private VatCalculator vatCalculator;
private Shipper shipper;
public OrderProcessor(VatCalculator vatCalculator, Shipper shipper) {
this.vatCalculator = vatCalculator;
this.shipper = shipper;
}
public void finaliseOrder(Order order) {
vatCalculator.addVat(order);
shipper.addShippingCosts(order);
// ... probably other stuff as well
}
}
public class FlatRateVatCalculator implements VatCalculator {
private VAT vat;
public FlatRateVatCalculator(VAT vat) {
this.vat = vat;
}
public void addVat(Order order) {
vat.addVat(order);
}
}
public class TargetCountryVatCalculator implements VatCalculator {
private Map<Country, VAT> vatsForCountry;
public TargetCountryVatCalculator(Map<Country, VAT> vatsForCountry) {
vatsForCountry = ImmutableMap.copyOf(vatsForCountry);
}
public void addVat(Order order) {
VAT actualVAT = vatsForCountry.get(order.getCustomerCountry());
actualVAT.addVat(order);
}
}
// actual wiring is better done using a framework like Spring or Guice, but
// here's what it could look like if done manually
public OrderProcessor wireForUS() {
VatCalculator vatCalculator = new FlatRateVatCalculator(new WisconsinVAT());
Shipper shipper = new WisconsinShipper();
return new OrderProcessor(vatCalculator, shipper);
}
public OrderProcessor wireForEU() {
Map<Country, VAT> countryVats = new HashMap<>();
countryVATs.put(SWEDEN, new SwedenVAT());
countryVATs.put(POLAND, new PolandVAT());
VatCalculator vatCalculator = new TargetCountryVatCalculator(countryVats);
Shipper shipper = new EuShipper();
return new OrderProcessor(vatCalculator, shipper);
}
This gives the following benefits compared to the version without DI:
- Since you can now instantiate single nodes in the object graph, and inject mock objects as collaborators, every node (class) is testable in isolation.
- Since the wiring logic is separated from the business logic, the business logic classes get a clearer purpose (business logic only, no wiring) and are therefore simpler and more reusable.
- Since the wiring logic is separated from the business logic, wiring is defined in a single place. You can look in the wiring code or configuration and see what your runtime object graph will look like.
However, there are still a couple of problems:
- At the application level, there is a single object graph with objects that are wired together in the same way that needs to handle every use case. Since object interactions are frozen at startup time, objects need conditional logic (not well described in this example, I’m afraid) to deal with variations. This complicates the code and means that any single use case will most likely touch only a small fragment of the execution paths in the graph.
- Since in a real system, the single object graph to rule them all will be very large, functional testing – testing of the wiring and of object interactions in that particular configuration – is still hard or impossible.
- There’s too much indirection – note that the VatCalculator and VAT interfaces define what is essentially the same method.
This is where the use-case specific context idea from DCI comes to the rescue.
DCI+DI version
In DCI, there is a Context that knows how to configure a specific object graph – defining which objects should be playing which roles – for every use case. Something like this:
public class OrderProcessor {
private VAT vat;
private Shipper shipper;
public OrderProcessor(VAT vat, Shipper shipper, ...) {
this.vat = vat;
this.shipper = shipper;
}
public void finaliseOrder(Order order) {
vat.addVat(order);
shipper.addShippingCosts(order);
// ... probably other stuff as well
}
}
public UsOrderProcessingContext implements OrderProcessingContext {
private WisconsinVat wisconsinVat; // injected
private Shipper shipper; // injected
public OrderProcessor setup(Order order) {
// in real life, would most likely do some other things here
// to figure out other use-case-specific wiring
return new OrderProcessor(wisconsinVat, shipper);
}
}
public EuOrderProcessingContext implements OrderProcessingContext {
private Map<Country, VAT> vatsForCountry; // injected
private Shipper shipper; // injected
public OrderProcessor setup(Order order) {
// in real life, would most likely do some other things here
// to figure out other use-case-specific wiring
VAT vat = vatsForCountry.get(order.getCustomerCountry();
return new OrderProcessor(vat, shipper);
}
}
Note that dependency injection is being used to instantiate the contexts as well, and that it is possible to mix ‘normal’ static object graphs with dynamic, DCI-style graphs. In fact, I’m pretty sure the contexts should be part of a static graph of objects wired using traditional DI.
Compared to normal DI, we get the following advantages:
- Less indirection in the business logic because we don’t need to make up our minds about which path to take – note that the VatCalculator interface and implementation are gone; their only reason for existing was to select the correct implementation of VAT. Simpler and clearer business logic is great.
- The object graph is tight, every object in the graph is actually used in the use case.
- Since the object graphs for each use case contain subsets of all the objects in the application, it should be easier to create automated functional tests that actually cover a large part of the object graph.
The main disadvantage I can see without having tested this in practice is that the wiring logic is now complex, which is normally a no-no (see for instance DIY-DI). There might also be quite a lot of contexts, depending on how many and how different the use cases are. On the other hand, it’s not more complex than any other code you write, and it is simple to increase your confidence in it through unit testing – which is something that is hard with for instance wiring done using traditional Spring config files. So maybe that’s not such a big deal.
So separating out the logic for wiring up your application from the business logic has the advantage of simplifying the business logic by making it more targeted, and of making the business logic more reusable by removing use-case-specific conditional logic and/or indirection from it. It also clarifies the program structure by making it specific to a use case and explicitly defined, either dynamically in contexts or statically in DI configuration files or code. Good stuff!
A Point of Injecting Code into Objects
The second thing I understood came from watching Trygve Reenskaug’s talk at Øredev last year. He demoed the Interactions perspective in BabyIDE, and showed how the roles in the arrows example interact. That view was pretty eye-opening for me (it’s about 1h 10mins into the talk), because it showed how you could extract the code that objects run to execute a distributed algorithm and look at only that code in isolation from other code in the objects. So the roles defined in a particular context are tightly tied in with each other, making up a specific distributed algorithm. Looking at that code separately from the actual objects that will execute it at runtime means you can highlight the distributed algorithm and make it readable.
So, clearly, if you want to separate an algorithm into pieces that should be executed by different objects without a central controlling object, injecting algorithms into objects gives you an advantage over injecting objects into an algorithm. Of course, the example algorithm from the talk is pretty trivial and could equally well be implemented with a central controlling object that draws arrows between the shapes that play the roles. Such an algorithm would also be even easier to overview than the fragmented one in the example, but that observation may not always be true. The difficult thing about architecture is that you have to see how it works in a large system before you know if it is good or not – small systems always look neat.
So with DCI proper, you can do things you can’t with DCI/DI – it is more powerful. But without an IDE that can extract related roles and highlight their interactions, I think that understanding a system with many different contexts and sets of interacting roles could get very complex. I guess I’m not entirely sure that the freedom to more easily distribute algorithm pieces to different objects is an unequivocally good thing in terms of writing code that is simple. And simple is incredibly important.
Conclusion
I still really like the thought of doing DCI but using DI to inject objects into algorithms instead of algorithms into objects. I think it can help simplify the business logic as well as make the system’s runtime structure easier to understand. I think DCI/DI does at least as well as DCI proper in addressing a point that Trygve Reenskaug comes back to – the GOF statement that “code won’t reveal everything about how a system will work”. Compared to DCI proper, DCI/DI may be weaker in terms of flexibility, but it has a couple advantages, too:
- You can do it even in a language that doesn’t allow dynamically adding/removing code to objects.
- Dynamically changing which code an object has access to feels like it may be an area that contains certain pitfalls, not least from a concurrency perspective. We’re having enough trouble thinking about concurrency as it is, and adding “which code can I execute right now” to an object’s mutable state seems like it could potentially open a can of worms.
I am still not completely sure that I am right about DI being a worthy substitute for class composition in DCI, but I have increased my confidence that it is. And anyway, it probably doesn’t matter too much to me personally, since, using dynamic, context-based DI looks like an extremely promising technique compared to the static DI that I am using today. I really feel like trying DCI/DI out in a larger context to see if it keeps its promises, but I am less comfortable about DCI proper due to the technical and conceptual risks involved in dynamically injecting code into objects.

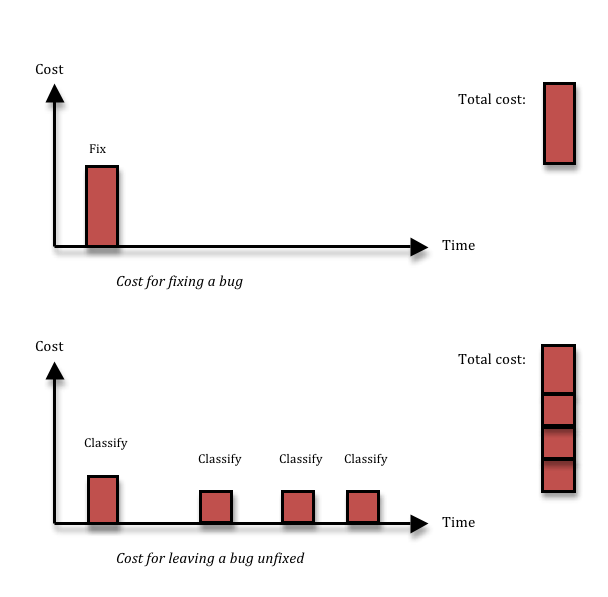{kind=link}
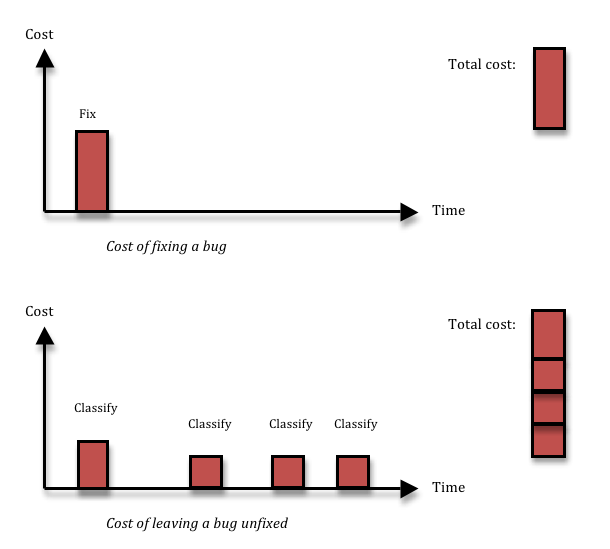{kind=link}