Posts Tagged Software Development
Qualities of Quality
Posted by Petter Måhlén in Software Development on April 10, 2014
[This is a slightly modified cross-post of something I wrote for the internal Spotify blog.]
I’m currently on parental leave, which is something that leaves very little time for any concentrated work effort because your first priority is to be on-call to solve the problems of a baby and you get interrupted all the time. But in between interruptions you can reflect on things and sometimes respond to email threads. I’ve been thinking about one topic in particular, namely quality, over the last week or two, and now my son is asleep, so I’m going to try to write up a blog post about it. In this post, I’m making the claim that
Developer-facing quality is a completely different thing from end-user facing quality, and is usually more important.
In one of the email threads I’ve been responding to at work, I said that “near-perfect quality code is … a meta-feature” meaning it affects and improves all other features, and that “it’s really a requirement to achieve sustainable speed”. I now think I can express that more precisely by considering different kinds of quality. The kind of quality I believe most people think about is what the end user experiences: product quality. Bugs, UI inconsistencies, etc. Product quality is a (non-functional) feature like any other, and can rightly be prioritised relative to other product features, such as performance, an improved design, a better recommendation algorithm and so on. The kind of quality that is a meta-feature is the quality a developer experiences, what I would term implementation quality. Things like readability and understandability of the code, ease of re-use, and bug-free-ness. Implementation quality doesn’t affect the end user experience, but it impacts the productivity of the teams working on improving the end user experience. These two kinds of quality overlap but are not the same:

While a product can be compelling even if it has poor product quality and therefore a tradeoff between product quality and other product features is meaningful, it’s much harder to motivate not paying attention to implementation quality. Poor implementation quality kills your ability to add features and evolve your product and therefore makes poor product quality a much more serious problem. Poor implementation quality becomes an obstacle to changing your product, and changing the product quickly is key to getting it right.
A very closely related thought is Martin Fowler’s Design Stamina Hypothesis, which is an article you really should read and understand. So I’m not going to summarise it here, just go ahead and read it. Seriously, read it. Done? OK, now spend 4.43 minutes watching Ward Cunningham explaining (technical) debt. Even if you’ve watched that presentation before, it’ll be ~5 minutes very well spent.
Cunningham says that it can be a good idea to take on debt if you’re saying “I don’t understand this domain well enough to know that I’m building the right features or that I’m using the right abstractions for the features I’m building”. The first kind of debt is what Eric Ries is addressing in the lean startup movement, and what we’re addressing at Spotify with the Think It, Build It, Ship It, Tweak It mantra. The second kind is something you should take on and need to continually pay back as you get the required understanding of your domain. It’s not OK to take on debt by not following good engineering practices and, for instance, not cleaning up your code once you’ve made it work. It should be easy to understand the abstractions you’ve chosen, even if they’re not the right ones. Paying back debt should be mostly about fixing your design as you better understand what it should have been, not about fixing bugs or spaghetti code.
The two most important points Fowler makes, I think, are the narrowness of the time interval during which it is meaningful to trade off design/implementation quality for speed, and that once you’re past the point where the two curves intersect, continuing to disregard implementation quality just slows you down further. You can only profitably trade off implementation quality for speed in very short-lived projects. Probably, if you’re expecting a system to have a lifespan of more than a couple of weeks, it’s a good idea to pay attention to implementation quality right from the start. I think there may be exceptions, when you desperately need to get some feature out to survive. But most places are not struggling to survive from day to day, they’re doing things like figuring out how to build the best music streaming service in history. That’s hard, so we need to make sure that we can adapt our product quickly and easily as we learn how to do it.
In the figure above, I included simplicity as an aspect of both product and implementation quality. This is primarily due to a couple of thoughts: first, an article by Andres Kutt, where especially the section on what he calls functional architecture is relevant. The point he is making is that due to the huge number of features in the Skype web store, it ended up in a state where it was almost impossible to make changes to it. Feature count makes users confused (hence it’s a product quality issue) and it adds code complexity, making the code base less amenable to change. It’s a mistake to think that a feature is free just because you’re not doing active development on it.
A couple of notes on bugs. I include that in both product and implementation quality. The product perspective is pretty obvious – bugs detract from the user experience – but the implementation aspects may be a little less apparent. The first aspect is of course that it’s easier to build something on top of a solid component than a library. So if services and libraries are bug free, it’s easier to make sure that the end user experience is good. But there’s a second aspect as well. Bugs reduce productivity in many ways – for a longer discussion, see this post. The short of it is that unfixed bugs in your code lead to additional meetings, bug management overhead, duplicate reports of the same bug and context switching. So a lot of the time, the best thing you can do for your own productivity is to just fix pretty much everything that’s ever reported.
One common misconception about quality and its impact on delivery speed is that things like pluggability/extensibility/configurability of some technical solution are quality. Those are things often labelled as over-engineering. To me, over-engineering is engineers adding waste by inventing features that aren’t actually really needed. The notorious 2002 Standish Group report on feature use concluded that 64% of product features are rarely or never used. Considering that features interact in ways that make code less malleable, the best thing you can do for your own and your team’s productivity is to question any feature that goes into the product you’re working on. Especially if you came up with it yourself. At Spotify, product owners get their scope creep tendencies kept in check by Think It, etc., but nobody really checks that we engineers limit the scope of the code we write. Over-engineering is not about creating something with too good implementation quality, it’s creating something with too many features. In nearly two decades of doing professional software development, I don’t think I ever felt a team I worked in overspent seriously on implementation quality, but I’ve definitely many times felt that we’ve wasted hugely on some feature or other.
I’ve also got some opinions about the use of TDD to drive implementation quality, but my son is going to wake up any minute, so that will have to remain a topic for a future blog post. :) For now, a summary of this post in two bullet points – to be able to move fast with product development, you need to:
- Be ruthless about minimising the feature count, and
- Always pay very close attention to implementation quality – but feel free to trade off product quality if needed.
Product Development vs Productivity Development
Posted by Petter Måhlén in Software Development on August 31, 2012
A couple of years ago, the team I was in started to use a concept we called gradual refactoring, whereby we would allocate a fixed percentage of our capacity to doing refactoring in order to keep technical debt at bay. That worked pretty well, and has been refined over the years into something we now tend to call the Productivity Backlog, in contrast to the normal Product Backlog. The way we use this idea boils down to reserving a more-or-less fixed percentage of overall capacity to improving that capacity. This is typically refactoring or cleaning up old, hard-to-change code or building or improving tools to help with something that slows us down. Normally those tools help us automate some process, making it less error-prone and less labour-intensive.
This works really well. Initially, I wanted to keep productivity efforts as part of the normal backlog, because I wanted a global prioritisation order. “All we need is to get really good at weighing medium to long-term benefits of productivity improvements vs the shorter term benefits from the product improvements”. That has turned out to be even harder in practice than I had thought. It’s just easier to keep things separate, for the following reasons:
- It’s an easier sell to the non-technical parts of/people in the organisation. “Continuous improvement” is something almost all organisations would like to do, and keeping a Productivity Backlog is an easy way to formalise that at a team level.
- It means that, as a technical person, you don’t have to try to sell the benefits of intangible things like “refactoring” or “eliminating technical debt” each time you need to untangle something particularly troublesome in your code base.
- It means that, as a business person, you don’t need to try to understand the reasons why some code is poorly suitable to some task or other, freeing you up to focus more clearly on figuring out what features and changes will make the product more successful in the future.
- It simplifies prioritisation both on the product and the productivity side, because a) you are comparing apples with apples (or at least fruits with fruits, if you know what I mean) on both backlogs and b) you can have different owners who can structure and order their own backlog without a need to coordinate needs and requirements from the other one.
- It provides an easy knob to turn as needs change – if you urgently need to get some product feature out, you can easily turn the productivity backlog down to 10% or even 5%. And if you’re suffering acutely from wasted time due to inefficient deployment procedures, you can turn it up to 20-25% until you’ve solved that crisis. If you do things on a case-by-case basis, you have to weigh the benefits of saving 3 minutes each time somebody needs to deploy a particular build of something somewhere against trying out a new front page to improve conversion, something that is hard and requires people with different types of expertise to understand each other’s problems and agree to a compromise.
Some of the issues we’ve had in using this concept have been around figuring out what types of changes should go on it. Initially, we called it the ‘tech backlog’, because it was owned by ‘tech’ and dealt very much with issues in implementation. That led to attempts at adding things like performance problems/measurement, or bug fixes driven more by technology than by the business side of things (like things getting logged that made real problems hard to find even though there was no obvious end-user impact). But those things are product features – quality and performance are clearly features in the product. Productivity is about the team’s ability to deliver more product features over time. That means it can be about fixing bugs, if those bugs, for instance, mean that deployment occasionally fail. But most of the time, it’s about removing obstacles and frustrations that keep us from delivering the product improvements that are what we get our job satisfaction from.
Productivity backlogs, compared to product backlogs, are reactive more than proactive. You feel the pain of some faulty process or code, and when it grows unbearable, you add fixing it near the top of your productivity backlog. There’s very little point in having long term goals for a productivity backlog.
A separate productivity backlog makes life simpler for both the business and the delivery side of things, is a great way to formalise continuous improvement and helps improve job satisfaction in delivery teams partly by removing obstacles to productivity and partly by providing knowledge (or hope at least) that the muck you’re having to wade through at the moment will at some point in the future be cleared out. Everybody should have one!
Exceptional iterators using Guava
Posted by Petter Måhlén in Software Development on April 23, 2012
Some years ago, I came across a little gem of a blog post about using a class called AbstractIterator that I hadn’t heard of before. I immediately loved it, and started using it, and in general, the APIs defined in the JDK collections classes a lot more frequently. I’m still doing that today, but for the first time, I came across a situation where AbstractIterator (nowadays in Guava, not Google Collections, of course) let me down.
In the system I’m currently working on, we need to process tens of thousands of feeds that are generated ‘a little randomly’, often by people without deep technical skills. This means we cannot know for sure that entries in the feeds will be consistent; we may be able to parse the first four entries, but not the fifth, and so on. The quantity of feeds, combined with the fact that we need to be forgiving of less-than-perfect input means that we need to be able to continue ingesting data even if a few entries are bad.
Ideally, we wanted to write code similar to this:
Iterator iterator = feedParser.iterator();
while (iterator.hasNext()) {
try {
FeedEntry entry = iterator.next();
// ... process the entry
}
catch (BadEntryException e) {
// .. track the error and continue processing
}
}
Now, we also wanted to use AbstractIterator as the base class for the parser to use, maybe something like:
class FeedEntryIterator extends AbstractIterator<FeedEntry> {
protected FeedEntry computeNext() {
if (noMoreInput()) {
return endOfData();
}
try {
return parseInput();
}
catch (ParseException e) {
throw new BadEntryException(e);
}
}
}
This, however, doesn’t work for two reasons:
- The BadEntryException will be thrown during the execution of hasNext(), since the AbstractIterator class calls the computeNext() method to check if any more data is available, storing the result in an intermediate member field until the next() method is called.
- If the computeNext() method throws an exception, the AbstractIterator is left in a state FAILED, from which it cannot recover.
One option to work around this that I thought of was delegation. Something like this works for many scenarios:
public class ForwardingTransformingIterator<F, T> implements Iterator<T> {
private final Iterator<F> source;
private final Function<F, T> transformer;
public ForwardingThrowingIterator(Iterator<F> source, Function<V, T> transformer) {
this.delegate = delegate;
this.transformer = transformer;
}
@Override
public boolean hasNext() {
return delegate.hasNext();
}
@Override
public T next() {
return transformer.apply(delegate.next());
}
}
The transformation function could then safely throw exceptions for entries it fails to parse. There’s even a shorthand for the above code in Guava: Iterators.transform(). The only issue is that the delegate iterator needs to return chunks of data that are the same size as what the parser/transform needs. So if the parser needs to be, for instance, something like a SAX parser, you’re in trouble. When I had gotten this far, I figured the only solution was to modify the AbstractIterator class so that it can deal with exceptions directly. The source is a little too long to include in an already source-heavy post, but there’s a gist here. The essence of the change is to make the base class store exceptions of a particular type that are thrown by computeNext(), and re-throw them instead of returning a value when next() is called. It kind of works (we’re using this implementation right now), but it would be nice to find a better solution.
I’ve created a Guava issue for this, so if you think this would be useful, go ahead and vote for it. And if you have suggestions for how to improve the code, feel free to make them here or at code.google.com!
If it’s Broken, Fix It
Posted by Petter Måhlén in Software Development on April 8, 2011
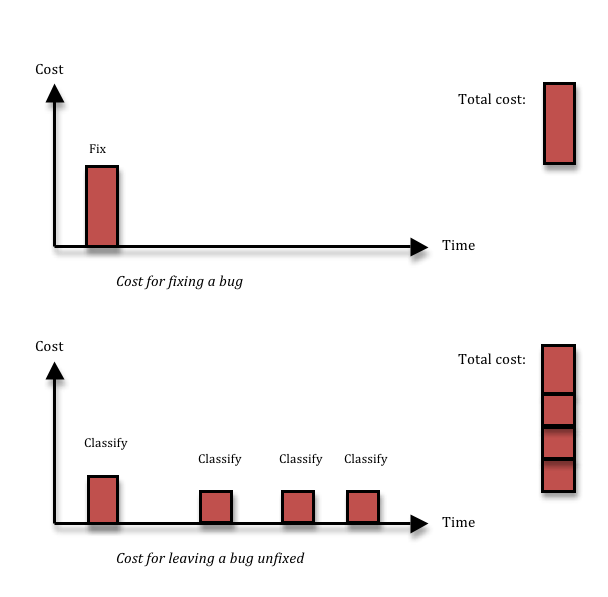
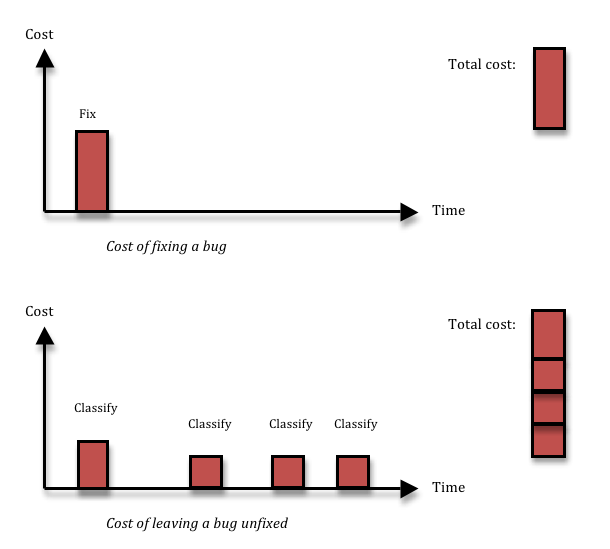
A search for terms like “bug classification” or “bug priority” gives a lot of results with lots of information about how to distinguish bug severity from bug priority, methods to use to ensure that you only fix the relevant bugs, what the correct set of severities are (is it Blocker, Major, Minor, Cosmetic, or should there be a Critical in there as well?), and so on. More and more, I’m starting to think that all that is mostly rubbish, and things are actually a lot simpler. In 95% of the cases, if you have found a bug, you should fix it right then and there, without wasting any time on prioritising or classifying it. Here’s why:

Fixing a bug means you incur a cost, and that’s the reason why people want to avoid fixing bugs that aren’t important. Cost-cutting is a great thing. The problem is, not fixing a bug also has a cost. If you decide to leave some inconsequential thing broken in your system, most likely, you’ll run into the same thing again three months down the line, by which time you’ll have forgotten that you had ever seen it before. Or, equally likely, somebody else will run into it next week. Each time somebody finds the thing again, you’ll waste a couple of hours on figuring out what it is, reporting it, classifying and prioritising it, realising it’s a dupe, and then forgetting about it again. Given enough time, that long term cost is going to be larger than the upfront fixing cost that you avoided.
What’s more, just having a process for prioritising bugs is far from free. Usually, you will want the person who does the prioritisation to be a business guy rather than a QA or development guy. Maybe the product owner, if you’re doing Scrum. That means that for every bug, she will have to stop what she is doing, switch contexts and understand the bug. She will want to understand from a developer if it is easy or hard to fix, and she will want to assess the business cost of leaving it unfixed. Then she can select a priority and add it to the queue of bugs that should be fixed. In the mean time, work on the story where the bug was found is stalled, so the QA and developer might have to context switch as well, and do some work on something else for a while – chances are the product owner won’t be available to prioritise bugs at a moment’s notice. Instead, she might be doing that once per day or even less frequently. All this leads to costly context switching, additional communication and waiting time.
The solution I advocate is simple: don’t waste time talking about bugs, just fix them. The majority of bugs can be fixed in 1-5 hours (depending of course on the quality of your code structure). Just having a bug prioritisation process will almost certainly take 1-3 man-hours per bug, since it involves many people and these people need to find the time to talk together so that they all understand enough about the problem. The cost might be even larger if you take context switching and stall times due to slow decision-making into account. And if you add the cost of having to deal with duplicate bugs over time, it’s very hard to argue that you will save anything by not fixing a bug. There are exceptions, of course. First, time is a factor; the decision not to fix will always be cost effective from a very short perspective, and always wasteful from a very long perspective. Second, the harder the bug is to fix, and the less likely it is to happen, the less likely is it that you’ll recover the up-front cost of fixing the bug by avoiding long-term costs due to the bug recurring. I think it should be up to the developer whose job it is to fix the bug to raise his hand if it looks likely to fit into the hard-to-fix-and-unlikely-to-happen category. My experience tells me that less than 5% of all bugs fit into this bucket – I just had a look at the last 40 bugs opened in my current project, and none of those belonged there. Anyway, for those bugs, you will need to make a more careful decision, so you need the cost of a prioritisation process. That means you can reduce the number of bugs you have to prioritise by a factor 20, or perhaps more. Lots less context-switching and administration in the short perspective, and lots less duplicated bug classification work in the longer perspective.
Note that the arguments I’m using are completely independent of the cost of the bug in terms of product quality. I’m just talking about development team productivity, not how end users react to the bug. I was in a discussion the other day with some former colleagues who were complaining that the people in charge of the business didn’t allow them to fix bugs. But the arguments they had been using were all in terms of product quality. That is something that (rightly, I think) tends to make business people suspicious. We as engineers want to make ‘good stuff’. Good quality code that we can be proud of. But the connection between our pride in our work and the company’s bottom line is very tenuous – not nonexistent, but weak. I want to be proud of what I do, and what’s more, I spend almost all of my time immersed in our technical solutions. This gives me a strong bias towards thinking that technical problems are important. A smart business person knows this and takes this into account when weighing any statement I make. But to me, the best argument in favour of fixing almost all bugs without a bug prioritisation process only looks at the team’s productivity. You don’t need the product quality aspect, although product quality and end-user experience is of course an additional reason to fix virtually all bugs.
So, it is true that there are cases when you want to hold off fixing a bug, or even decide to leave it in the system unfixed. But those cases are very rare. In general, if you want to be an effective software development team, don’t make it so complicated. Don’t prioritise bugs. If it’s broken, fix it. You’ll be developing stuff faster and as an added bonus, your users will get a better quality system.
The Power of Standardisation
Posted by Petter Måhlén in Software Development on December 2, 2010
A couple of recent events made me see the value of company-internal standardisation in a way that I hadn’t before. Obviously, reusing standardised solutions for software development is a good thing, as it is easier to understand them. But I’ve always rated continuous evolution of your technologies and choosing the best tool for the problem at hand higher. I’m beginning to think that was wrong, and that company-internal standards are or can be a very important consideration when choosing solutions.
Let’s get to the examples. First, we’ve had a set of automated functional regression tests that we can run against our sites for quite some time. But since the guy who developed those tests left, it has turned out that we can’t run them any more. The reason is that they were developed using Perl, a programming language that most of the team members are not very comfortable with, and that the way you would run them involved making some manual modifications to certain configuration files, then selecting the right ‘main’ file to execute. We’ve recently started replacing those tests with new ones written in Java and controlled by TestNG. This means it was trivial for us to run the tests through Maven. Some slight cleverness (quite possibly a topic for another blog post) allows us to run the tests for different combinations of sites (our team runs 8 different sites with similar but not identical functionality) and browsers using commands like this:
mvn test -Pall-sites -Pfirefox -Pchrome -Pstage
This meant it was trivial to get Hudson to run these tests for us against the staging environment and that both developers and QA can run the tests at any time.
The second example is also related to automated testing – we’ve started creating a new framework for managing our performance tests. We’ve come to the conclusion that our team in the EU has different needs to the team in the US that maintains our current framework, and in the interest of perfect agility, we should be able to improve our productivity by owning the tools we work with. We just deployed the first couple of versions of that tool, and our QA Lead immediately told me that he felt that even though the tool is still far inferior to the one it will eventually replace, he was really happy to have a plain Java service to deploy as opposed to the current Perl/CGI-based framework. Since Java services are our bread and butter at Shopzilla (I’ve lost count, but our systems probably include about 30-50 services, most of which are written in Java and use almost RESTful HTTP+XML APIs), we have great tools that support automated deployment and monitoring of these services.
The final example was a program for batch processing of files that we need for a new feature. Our initial solution was a plain Java executable that monitored a set of directories for files to process. However, it quickly became obvious that we didn’t know how to deal with that from a configuration management/system operations perspective. So even though the development and QA was done, and the program worked, we decided to refit it as one of our standard Java services, with a feature to upload files via POST requests instead of monitoring directories.
In all of these cases, there are a few things that come to mind:
- We’ve invested a lot in creating tools and processes around managing Java services that are deployed as WARs into Tomcat. Doing that is dead easy for us.
- We get a lot of common features for free when reusing this deployment form: standard solutions for setting server-specific configuration parameters, logging, load balancing, debugging, build numbers, etc.
- Every single person working here is familiar with our standard Java/Tomcat services. Developers know where to find the source code and where the entry points are. QA knows where to find log files, how to deploy builds for testing and how to check the current configuration. CM knows how to configure environments and how to set up monitoring tools, and so on.
I think there is a tendency among developers – certainly with me – to think only about their own part when choosing the tools and technologies for developing something new. So if I would be an expert in, say, Ruby on Rails, it would probably be very easy for me to create some kind of database admin tool using that. But everybody else would struggle with figuring out how to deal with it – where can I find the logs, how do I build it, how is it deployed and how do I set up monitoring?
There is definitely a tradeoff to be made between being productive today with existing tools and technologies and being productive tomorrow through migrating to newer and better ones. I think I’ve not had enough understanding of how much smoother the path can be if you stay with the standard solutions compared to introducing new technologies. My preference has always been to do gradual, almost continuous migration to newer tools and technologies, to the point of having that as an explicit strategy at Jadestone a few years ago. I am now beginning to think it’s quite possible that it is better to do technology migrations as larger, more discrete events where a whole ecosystem is changed or created at the same time. In the three cases above, we’re staying on old, familiar territory. That’s the path of least resistance and most bang for the buck.
Making No Mistakes is a Mistake
Posted by Petter Måhlén in Software Development on June 9, 2010
Here’s one of my favourite diagrams:

What it shows is an extremely common situation – an axis, where one type of cost is very large at one end of the scale (red line), and a conflicting type of cost is very large at the other end of the scale (green line). The total cost (purple line) has an optimum somewhere between the extremes. I mentioned one such situation when talking about teams working in isolation or interfering with each other. To me, another example is doing design up-front. If you don’t do any design before starting to write a significant piece of code, you’re likely to go very wrong – if nothing else, in terms of performance or scalability, which are hard to engineer in at a late stage. But on the other hand, Big Design Up Front typically means that you waste a lot of time solving problems that, once you get down to the details, turn out never to have needed solutions. It’s also easier to come up with a good design in the context of a partially coded, conctrete system than for something that is all blue-prints and abstract. So at one end of the scale, you do no design before you write code, and you run a risk of incurring huge costs due to mistakes that could have been avoided by a little planning. And at the other end of the scale, you do a lot of design before coding, and you probably spend way too much time agonizing over perceived problems that you in fact never run into once you start writing the code. And somewhere in the middle is the sweet spot where you want to be – doing lagom design to use a Swedish term.
The diagram shows a useful way of thinking about situations for two reasons: first, these situations are very common, so you can use it often, and second, people (myself very much included) often tend to see only one of the pressures. “If we don’t write this design document, it will be harder for new hires to understand how the system works, so we must write it!” True, but how often will we have new hires that need to understand the system, how much easier will a design document make this understanding, and how much time will it take to write the document and keep it up to date? A lot of the time, the focus on one of these pressures comes from a strong feeling of what is “the proper way to do things”, which can lead to flame wars on the web or heated debates within a company or team. An awareness of the fact that costs are not absolute – it is not the end of the world if it takes some time for a new hire to understand the system design, and a document isn’t going to make that cost zero anyway – and of the fact that there is a need to weigh two types of costs against each other can make it easier to make good decisions and have productive debates.
For me, a particularly interesting example of conflicting pressures is where work processes are concerned. I think it is fair to say that they are introduced to prevent mistakes of different kinds. With inadequate processes, you run a risk of losing a lot of time or money: lack of reporting leads to lack of management insight into a project, which results in worse decisions, lack of communication means that two people in different parts of the same room write two almost identical classes to solve the same problem, lack of quality assurance leads to poorly performing products and angry customers, etc. On the other hand, every process step you introduce comes with some sort of cost. It takes time to write a project report and time to read it. Somebody must probably be a central point of communication to ensure that individual programmers are aware of the types of problems that other programmers are working on, and verifying that something that “has always worked and we didn’t change” still works can be a big effort. So we have conflicting pressures: mistakes come with a cost, and process introduced to prevent those mistakes comes with some overhead.

As a side note, not all process steps are equal in terms of power-to-weight ratio. A somewhat strained example could be of a manager who is worried about his staff taking too long lunch breaks. He might require them to leave him written notes about when they start and finish their lunch. The process step will give him some sort of clearer picture of how much time they spend, but it comes at a cost in time and resentment caused by writing documents perceived as useless and an impression of a lack of trust. An example of a good power-to-weight ratio could be the daily standup in Scrum, which is a great way of ensuring that team members are up to date with what others are doing without wasting large amounts of time on it.
Getting back to the main point: when adopting or adapting work processes, we’ll want to find a sweet spot where we have enough process to ensure sufficient control over our mistakes, but where we don’t waste a lot of time doing things that don’t directly create value. Kurt Högnelid, who was my boss in 1998-1999, and who taught me most of what I know about managing people, pointed out something to me: at the sweet spot, you will make mistakes! This is counter-intuitive in some ways. During a retrospective, we tend to want to find out what went wrong and take action to prevent the same thing from happening again. But this diagram tells us that is sometimes wrong – if we have a situation where we never make mistakes, we’re in fact likely to be wasteful in that we’re probably overspending on prevention.
Different mistakes are different. If the product at hand is a medical system, it is likely that we want to ensure that we never make mistakes that lead it to be broken in ways that might harm people. The same thing is true of most systems where bugs would lead to large financial loss. But I definitely think that there is a tendency to overspend on preventing simple work-related mistakes through for instance too much planning or documentation, where rare mistakes are likely to cost less than the continuous over-investment in process. It takes a bit of daring to accept that things will go wrong and to see that as an indication of having found the right balance.
Just Do It – or Not
Posted by Petter Måhlén in Software Development on January 29, 2010
I just found myself disagreeing with me. I reread a blog post that I had written a week or two ago that was posted on the Shopzilla blog, and noticed that I had written that “metadata is as important as the primary data (well, close enough that the difference doesn’t really matter)”. That was wrong. There is actually no difference in importance between the two. This is because importance is actually binary: either you have to do something, or you don’t.
I’ve found myself using more fine-grained definitions of relative importance of things before, and I thought it was a good thing to do. Having different severity levels for bugs, for instance, felt right: there seemed to be a difference between a blocker, a normal-level one and a cosmetic bug. Over time, I’ve come to realise that there are only two classes of bugs: those you can live with and those you can’t. The latter must be fixed, the former don’t have to be. And the corollary of that is that it’s always going to be more important to add another feature than to fix a bug that you can live with, so the bugs you don’t have to fix should just be put into some bucket where they can live undisturbed forever.
I remember some years ago, when Microsoft released a Windows version that had something like 35,000 known bugs in it, and how some people were upset about that. “How can they release something that has so many bugs?” I think that is (or at least can be) a perfectly OK thing to do, it just means that you’ve tested your software thoroughly and know the quality status of it. The remaining bugs are things you’ve decided not to fix.
Getting back to the topic of priority again: that is another thing, it’s not the same as importance. I think of it as a two-dimensional thing, where importance is one axis and urgency is the other. Say you have five things to do, A through E. As soon as you get E done, you’ll increase your revenue by around 3%, but before you can do E, you need to do D. A is a bug that you really want to fix, B is a document that you ought to write according to the company standard process, but that nobody will ever read, and C is a bug that you in all honesty don’t need to fix even if it annoys you. This diagram shows how I would do prioritisation in that case.

The unimportant things get an urgency of zero. We don’t need to do them, so let’s just not do them (although the best thing to do about that document is to change the company process that requires doing work that is wasteful). The urgency values assigned to the important things are based on their intrinsic value and on dependencies between them.
I’ve been guilty of the sin of having lots of half-finished items on my daily todo-list. Often, the reason why I didn’t finish those things was that they were actually not that important, but I still didn’t take them off the list. This led to more stress and ‘mental overhead’. It is a common situation, I think. I also think it is very detrimental to productivity. If you want to be great at executing, I think that a certain ruthlessness about deciding what should be done – and more to the point, what should not – and lots of discipline about actually doing it is necessary. Here are two rules I try to follow:
- If you have to do it, just do it – and finish it. Really. All the way.
- If you don’t have to do it, there’s no excuse for doing it. So don’t even think about it – put it on a pile of stuff that you can forget about and make sure it doesn’t worry you.

{kind=link}
{kind=link}