Posts Tagged Automated Testing
BDD using Lettuce vs Cucumber-JVM
Posted by Petter Måhlén in Software Development on May 23, 2012
I’ve now been working for more than 8 months on a project where we’ve been using BDD and creating high-level tests written in Gherkin before actually going on to implement the features themselves. It’s the first time I’m using BDD, so it’s been very interesting. The main conclusion is that it’s a very useful thing to do – writing a high level test really helps me determine how things should work, and I think it makes the implementation cleaner. I can’t say I have conclusive evidence that we’ve got fewer regression bugs as a result of our BDD tests, but at least we’ve got comprehensive regression/acceptance tests that are fully automated. Another BDD reflection is that I think it’ll take me some more time before I really feel I understand it; I’m still not sure I get things like how best to structure the testing code from the perspective of making tests very robust to changes in features. That may be a topic for a future blog post, if and when I start feeling I have some insight into that.
So, BDD is a good thing, as far as I am concerned. This post is not about that; it’s about our experiences of using two different frameworks to execute the Gherkin tests: a Python-based one called Lettuce and Cucumber-JVM, using Java for the step definitions. We evaluated both during our project initiation, and made the decision to go with Lettuce. The primary reason was that we’re using Python for a lot of our automated testing company-wide, and it was felt that it would be easier to move from project to project if we kept to the same language. Cucumber-JVM wasn’t actually released yet at the time, but it felt stable (and the code is really well written) and was close to a release, so that didn’t factor heavily in the decision. For me, being essentially a Java-only developer, I felt that was an OK decision. I felt I would personally be more productive using Java than Python, and that Cucumber-JVM integrated better with our Maven-centric builds, but that it would be interesting to have a good excuse learn a new language.
Now, a few months down the line, we’ve made the decision to stop developing new tests using Lettuce and instead use Cucumber-JVM for new features. (More precisely, we will keep doing our big end-to-end tests using Lettuce, since we’ve got some really nice infrastructure code written in Python that helps us manage deployments and stuff, but the single-service tests will be Cucumber-JVM from now on).
The reasons for this decision are as outlined below – note that it’s hard for me having done about 20 times more Java development than Python to be completely objective about the languages as languages. I’ve tried to be explicit about those points that are clearly subjective.
- In my personal opinion, Python as a language lends itself better to ‘small, quick’ types of problems. Throughout the last few months, I’ve repeatedly been impressed by how often ‘just trying something’ in Python leads to the behaviour I was looking for. Also, since it is interpreted, experimenting can be really quick. However, in the case of running BDD tests, you’re actually not working on a ‘small, quick’ type of problem. Frequently, running the tests takes minutes because they require starting/restarting services, setting up databases, etc. That means that mistakes that the Java compiler/IDE would have told you about as you typed them can take a minute or so to discover, and that’s not great at all. I think dynamic languages require quick turnaround to give you any benefits from the reduced amount of typing you have to do to write code in them, and BDD doesn’t feel like a problem that lends itself to quick turnaround times.
- It’s hard to troubleshoot tests that are run via Lettuce. You can’t debug Python, and something (nose or Lettuce itself, I’m not sure) takes over the standard out, which means it’s hard to print out debug output. In our current implementation, we’re getting assertion errors divorced from the debug output, which makes it quite awkward to figure out what was the actual issue.
- We’ve had to spend a lot of effort on getting the necessary infrastructure together that allows us to do things like share code between BDD tests for different services, ensure that different environments run the same libraries, that we don’t have to install too many dependencies locally before being able to run a build on a given machine, etc. So we’re using things like pip to download and install dependencies, virtualised buildouts to ensure that we actually have the right versions of stuff without conflicting with the machine-global Python installation, and an internal cheeseshop for distributing our internal test utilities code. This is stuff that basically comes for free and in a better implementation when using Maven. When I say ‘better implementation’, I’m talking particularly about the dependency management, where Maven’s versioning of libraries feels like it is more mature and works better than Python eggs do.
- Since it’s possible to run Cucumber-JVM tests via JUnit, they slot directly into all the existing infrastructure around build tools and processes. This means that you can immediately view test results from the BDD tests in the same way as your unit tests, which is very useful (although there are still issues). For our Lettuce tests, on the other hand, we’ve had to hand-craft tools to plug in the test execution and result notification into Maven. And while it should be possible, we haven’t gotten around to actually integrating the output of those tools fully into Jenkins, Sonar, etc. This integration again just comes for free with Cucumber-JVM.
- Another advantage of having the tests runnable via JUnit is that it is trivial to run them from inside the IDE, which means you can use a debugger to do troubleshooting, that you can easily select which ones to run, etc.
- Finally, although we have no data to confirm this, it feels like running tests with Cucumber-JVM is faster than running via Lettuce. And that’s important as it makes it less painful to run the BDD tests more frequently. (EDIT: see comment below for some actual data to support this point)
For me, as an experienced Java hand and far from a polyglot programmer, it’s been very interesting to spend a few months with another language. I think I can safely summarise most of the advantages of Cucumber-JVM over Lettuce as coming from “Java vs Python as a platform” rather than “Java vs Python as a language” – with some implementation choices thrown in there and the fact that BDD as a problem doesn’t lend itself to quick turnaround, which makes static analysis more valuable.
In general, BDD has been a great experience so far, as has Cucumber-JVM and to a lesser degree Python. But from my perspective, Lettuce isn’t a great tool for writing BDD tests for Maven-based projects.
If it’s Broken, Fix It
Posted by Petter Måhlén in Software Development on April 8, 2011
A search for terms like “bug classification” or “bug priority” gives a lot of results with lots of information about how to distinguish bug severity from bug priority, methods to use to ensure that you only fix the relevant bugs, what the correct set of severities are (is it Blocker, Major, Minor, Cosmetic, or should there be a Critical in there as well?), and so on. More and more, I’m starting to think that all that is mostly rubbish, and things are actually a lot simpler. In 95% of the cases, if you have found a bug, you should fix it right then and there, without wasting any time on prioritising or classifying it. Here’s why:

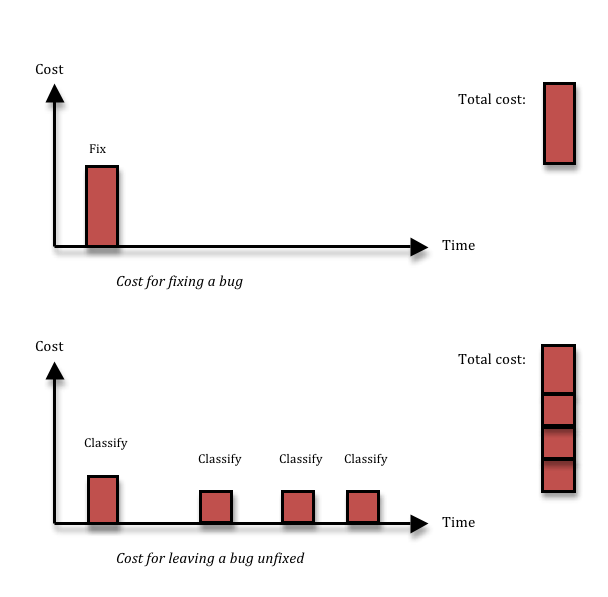
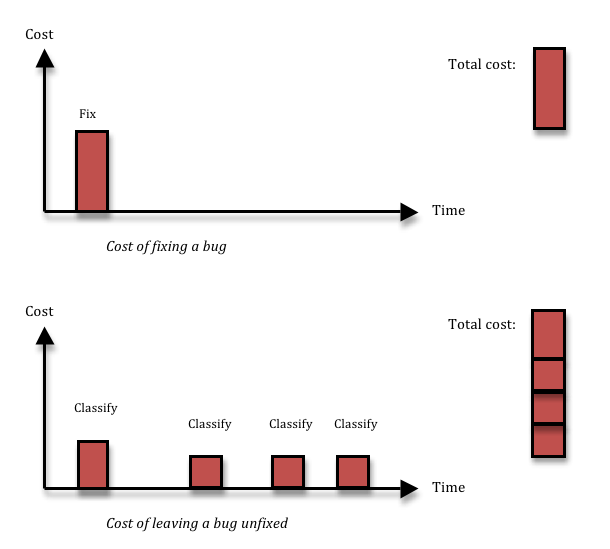
Fixing a bug means you incur a cost, and that’s the reason why people want to avoid fixing bugs that aren’t important. Cost-cutting is a great thing. The problem is, not fixing a bug also has a cost. If you decide to leave some inconsequential thing broken in your system, most likely, you’ll run into the same thing again three months down the line, by which time you’ll have forgotten that you had ever seen it before. Or, equally likely, somebody else will run into it next week. Each time somebody finds the thing again, you’ll waste a couple of hours on figuring out what it is, reporting it, classifying and prioritising it, realising it’s a dupe, and then forgetting about it again. Given enough time, that long term cost is going to be larger than the upfront fixing cost that you avoided.
What’s more, just having a process for prioritising bugs is far from free. Usually, you will want the person who does the prioritisation to be a business guy rather than a QA or development guy. Maybe the product owner, if you’re doing Scrum. That means that for every bug, she will have to stop what she is doing, switch contexts and understand the bug. She will want to understand from a developer if it is easy or hard to fix, and she will want to assess the business cost of leaving it unfixed. Then she can select a priority and add it to the queue of bugs that should be fixed. In the mean time, work on the story where the bug was found is stalled, so the QA and developer might have to context switch as well, and do some work on something else for a while – chances are the product owner won’t be available to prioritise bugs at a moment’s notice. Instead, she might be doing that once per day or even less frequently. All this leads to costly context switching, additional communication and waiting time.
The solution I advocate is simple: don’t waste time talking about bugs, just fix them. The majority of bugs can be fixed in 1-5 hours (depending of course on the quality of your code structure). Just having a bug prioritisation process will almost certainly take 1-3 man-hours per bug, since it involves many people and these people need to find the time to talk together so that they all understand enough about the problem. The cost might be even larger if you take context switching and stall times due to slow decision-making into account. And if you add the cost of having to deal with duplicate bugs over time, it’s very hard to argue that you will save anything by not fixing a bug. There are exceptions, of course. First, time is a factor; the decision not to fix will always be cost effective from a very short perspective, and always wasteful from a very long perspective. Second, the harder the bug is to fix, and the less likely it is to happen, the less likely is it that you’ll recover the up-front cost of fixing the bug by avoiding long-term costs due to the bug recurring. I think it should be up to the developer whose job it is to fix the bug to raise his hand if it looks likely to fit into the hard-to-fix-and-unlikely-to-happen category. My experience tells me that less than 5% of all bugs fit into this bucket – I just had a look at the last 40 bugs opened in my current project, and none of those belonged there. Anyway, for those bugs, you will need to make a more careful decision, so you need the cost of a prioritisation process. That means you can reduce the number of bugs you have to prioritise by a factor 20, or perhaps more. Lots less context-switching and administration in the short perspective, and lots less duplicated bug classification work in the longer perspective.
Note that the arguments I’m using are completely independent of the cost of the bug in terms of product quality. I’m just talking about development team productivity, not how end users react to the bug. I was in a discussion the other day with some former colleagues who were complaining that the people in charge of the business didn’t allow them to fix bugs. But the arguments they had been using were all in terms of product quality. That is something that (rightly, I think) tends to make business people suspicious. We as engineers want to make ‘good stuff’. Good quality code that we can be proud of. But the connection between our pride in our work and the company’s bottom line is very tenuous – not nonexistent, but weak. I want to be proud of what I do, and what’s more, I spend almost all of my time immersed in our technical solutions. This gives me a strong bias towards thinking that technical problems are important. A smart business person knows this and takes this into account when weighing any statement I make. But to me, the best argument in favour of fixing almost all bugs without a bug prioritisation process only looks at the team’s productivity. You don’t need the product quality aspect, although product quality and end-user experience is of course an additional reason to fix virtually all bugs.
So, it is true that there are cases when you want to hold off fixing a bug, or even decide to leave it in the system unfixed. But those cases are very rare. In general, if you want to be an effective software development team, don’t make it so complicated. Don’t prioritise bugs. If it’s broken, fix it. You’ll be developing stuff faster and as an added bonus, your users will get a better quality system.
Testing and Code Correctness
Posted by Petter Måhlén in Software Development on December 10, 2010
Lately, I’ve found myself disagreeing with such giants as Trygve Reenskaug and Tony Hoare, and thinking that I have understood something about software that maybe they have not. A nobody disagreeing with two famous professors! Can I have a point? Well, read on and make up your own mind about it.
Since discovering about Trygve’s brainchild DCI, I’ve been following the discussions on the Object Composition discussion group. I’m not participating actively in the discussions; the main reason for me following the group is that Trygve is active there, and he has a lot of profound insights into software development which makes reading his posts a joy. But I’ve found myself disagreeing with him on one or possibly two closely related points. In at least one of his talks, he makes the point that testing does not help you get quality into a product. All tests do is prove that a particular execution path with particular parameter values works, they say nothing about what will happen if some parameter values change, and no matter how much you test some code, you can’t say that it is bug-free. Instead, the way to get quality into code is through readability. He often quotes Tony Hoare, who said:
“There are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies and the other is to make it so complicated that there are no obvious deficiencies.”
This is a lovely and memorable quote, but as all soundbites, it is a simplification. In fact, I think it is simplified to the point of not being meaningful, and while I think that Trygve’s point about testing is correct, I also think it is not very important and a slightly dangerous point to make as it might discourage you from testing. Tests, especially automated ones, are critical when building quality software, even though they don’t put quality into the product. Let me start on why I don’t think Tony Hoare’s quote is great with two code examples.
Some code that works
public class Multiplier {
private static final double POINT_25 = 0.25;
public double multiplyByPoint25(double amount) {
return amount * POINT_25;
}
}
This code is simple, to the point where it obviously contains no deficiencies. It’s not particularly interesting, but a glance shows that it does what you’d expect it to. One point to Tony!
Some code that is broken
public class VatCalculator {
private static final double VAT_RATE = 0.25;
public double calculateVat(double amount) {
return amount * VAT_RATE;
}
}
This code is broken in at least two ways:
- It does monetary calculations using floating-point arithmetic. This means that calculations aren’t exact, and exactness is always a requirement when dealing with money (see for instance Effective Java, Item 48 for more on this).
- It is probably broken in more subtle ways as well. In Sweden, the default VAT rate is indeed 25% on top of the price before VAT. But most of the time, people in Sweden think about this backwards – the only price they see is the one with VAT, so some people prefer to multiply the total price by .2 to get the part of the total price that is VAT. We don’t know if the amount is the amount before VAT or the total amount including VAT. Also, the VAT rate depends on the item type, so if this method were called using the price of a pencil, it would probably give the right answer, but it wouldn’t for a book. And if the amount is the total of an order for a pencil and a book, it’s wrong in yet another way. The list of things that could be broken in terms of how to do VAT calculations goes on.
And the funny thing is, from a machine-instructions perspective, the two classes are of course identical! Why is the first one right, and the second one wrong, just because we changed some names? When the names changed, our perception of the programmer’s intent changed with them. Suddenly, the identical machine instructions have a more specific purpose, and we see more of the actual or probable business rules that should be applied. This makes the second version obviously broken because it uses floating-point arithmetic for monetary calculations. We understand enough about the programmer’s intent to find a mistake. But while the floating-point error is obvious, there is nothing in the code that gives us clear evidence as to whether the VAT calculation is correct in terms of the rate that is being applied or not.
Clearly, readability is not sufficient to guarantee correctness. Correct code meets its business requirements – the intent of the person who uses it for something. Readability can at best tell us if it meets the intent of the programmer that wrote it. This doesn’t mean readability is unimportant; on the contrary, readable code is a holy grail to be strived for at almost all cost. But it does mean that Tony Hoare’s goal is unachievable. The code by itself cannot “obviously have no deficiencies”, because the code only tells us what it does, not what it should do.
Testing to the Rescue
So how can we ensure that our code is correct? Well, we need well-defined requirements and the ability to match those requirements with what the code does. There are people whose full-time job is to define requirements; all they do is to formulate business users’ descriptions of what they do in terms that should be unambiguous, free of duplication, conflicts, and so on, so that programmers and testers can get a clear picture of what the code should actually be doing. There are whole toolsets for requirements analysis and management that help these people produce consistent and unambiguous definitions of requirements. Once that’s done the problem is of course that it’s really hard to know if your code actually meet all the requirements that are defined. No problem, there’s further tools and processes that support mapping the requirements to test cases, executions of these test cases and the defects found and fixed.
Like many others (this is at the heart of agile), I think all that is largely a waste of time. I’m not saying it doesn’t help, it’s just very inefficient. It’s practically impossible to formulate anything using natural language in a way that is unambiguous, consistent and understandable. And then mapping requirements defined using natural language to tests and test executions is again hard to the point of being impossible. The only languages we have that allow us to formulate statements unambiguously and with precision are formal systems such as programming languages. But wait, did I just say we can write something that has no ambiguity in code? Could we formulate our requirements using code? Yes, of course. Done right, that’s exactly what automated tests are.
If our automated tests reflect the intent of the users of the code, we can get an extremely detailed and precise specification of the requirements that has practically zero cost of verification. Since the specification is written in a programming language, it is written using one of the best tools we know how to design in terms of optimal unambiguity and readability. As we all know, programming languages have shortcomings there, but they are way superior to natural language.
The argument that business users won’t be able to understand tests/requirements written in code and that they therefore must be in natural language is easy to refute on two grounds: first, business users don’t understand a Word document or database with hundreds or thousands of requirements either (and neither do programmers), and second, let the code speak for itself. Business users can and do understand what your product does, and if it does the wrong thing, they can tell you. Fix the code (tests first), and ship a new version. Again, a core principle in agile.
I often come across a sentiment among developers that tests are restrictive (“I’ve fixed the code, why do I have to fix the test too”), or that you “haven’t got the time to write tests”. That’s a misunderstanding – done right, tests are liberating and save time. Liberating, because the fact that your tests specify how the code is intended to behave means that you don’t need to worry as much about breaking existing functionality. That enables you to have multiple teams co-owning the same code, which improves your agility. Maybe even more importantly, having a robust harness of tests around some code enables you to refactor it and thereby keep the code readable even in the face of evolution of the feature set it must support.
So that should hopefully explain why I think the point that Trygve made about tests not being able to get quality into a product is valid but not really important. The quality comes from the clarity of the system architecture, system design and code implementation, not from the tests. But automated tests enable you to keep quality in a product as it evolves by preventing regression errors and making it possible for you to keep the all-important clarity and readability up to date even as the code evolves.

{kind=link}
{kind=link}